Freifunk Forum
2015.1-stable-1 Released (Rheinufer)
Technik
Rheinufer
CyrusFox
12. Juni 2015 um 15:31
7
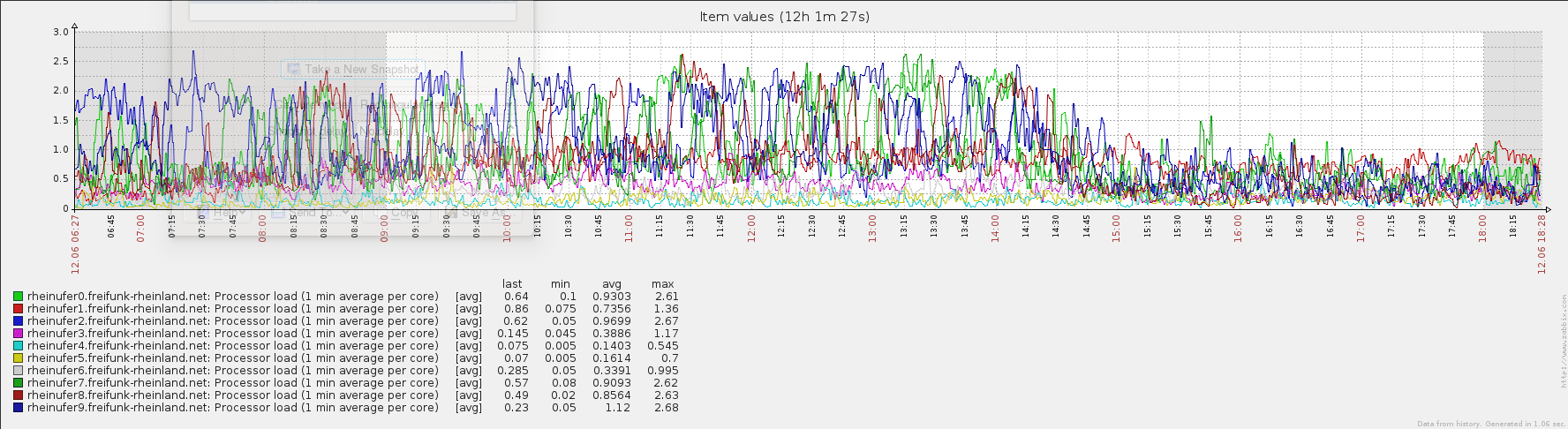
Kleiner Zwischenstand der CPU Auslastung auf den Supernodes:
cpu rheinufer supernodes.png
1776×486 339 KB
4 „Gefällt mir“
Reduzierung der fastd Tunnel auf 1 im Ruhrgebiet
Beitrag im Thema anzeigen