Und wieso collectd wo ihr doch schon Influx Produkte nutzt?
Yanic für jede einzelne Domain separiert - der yanic bindet auf den Siegburger Gateways jeweils an die fe80-Adresse, nicht global. Durch die getrennten .json Daten lassen sich dann später auch lokale Community-Maps einfacher aufsetzen.
Der http-collector (cronjob) zieht sich in Rhein Sieg auch Daten aus Troisdorf - mit älteren Yanic-Sourcen, die unabhängig von den Siegburger Servern laufen. Die yanics aus Troisdorf könnten auch direkt abliefern - tun sie halt nicht. Auf dem Map-Server sind im workflow auch optional ein paar perl-scripte hinterlegt, die importierte .json patchen können vor der Bereitstellung im meshviewer.
collectd macht nicht Node-Monitoring, sondern Server-Monitoring - da landen also keine nodeinfos in der Datenbank. Eine Grafana-Instanz kann so über die verschiedenen Datenbanken auf alle Ressourcen zugreifen und für’s Monitoring Alerts auslösen.
Der Statistik-Server läuft als VM im Proxmox - dort findet übergreifend auch das Firewalling statt.
2 „Gefällt mir“
Danke für die Erklärung, aber warum ihr collectd nutzt obwohl ihr eine InfluxDB habt erschließt sich mir immer noch nicht. Oder nutzt ihr fürs Server monitoring collectd-web ?
@comancho: collectd mit network plugin leitet die gesammelten Daten direkt an den collectd auf dem Statistik Server mit Authentifizierung weiter.
So können beliebige openwrt-Router mit collectd/Server mit collectd ihre Stats abliefern - z.B. beim Firmware-Bau:
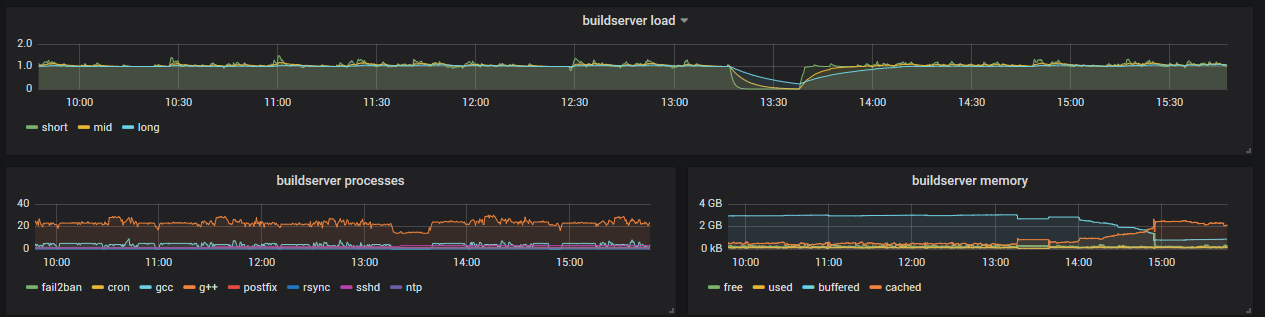
Der lokale collectd vom Statistik-Server macht connectivity checks auf die Gateways:
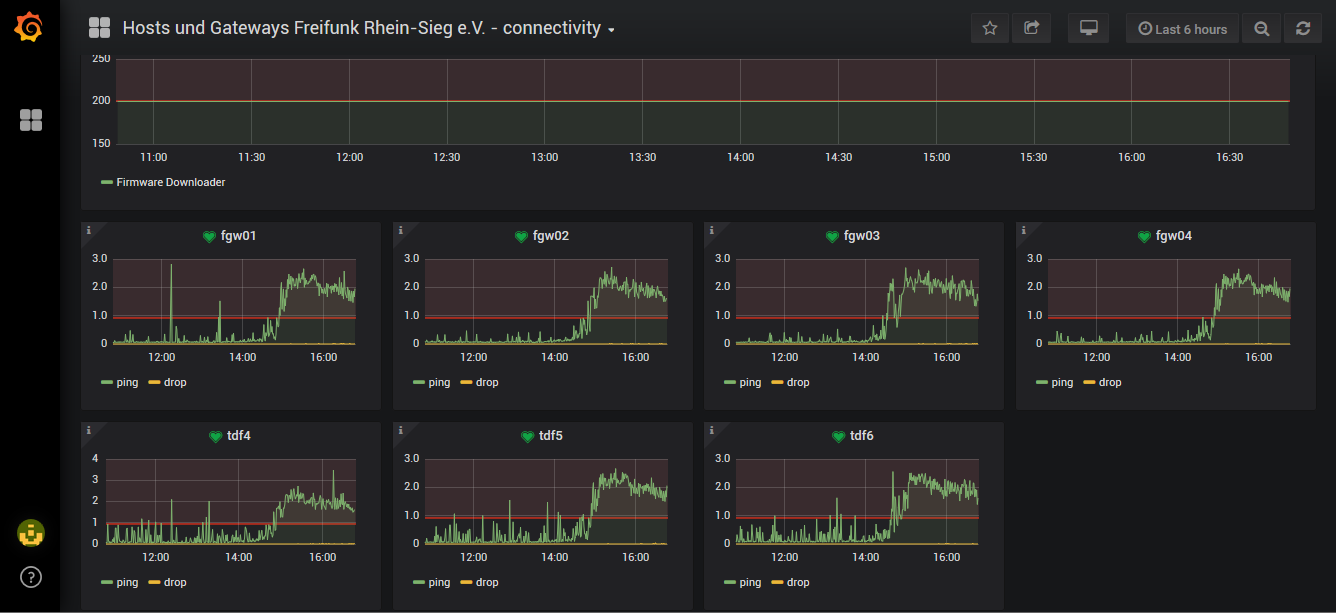
Vom Grafana gehen die Alerts per Mail raus und an einen #monitoring channel im Slack.
1 „Gefällt mir“