Auf die offiziellen Supernode wird der Subnetz 2a03:2260:xyz::/48 bekannt gegeben.
Auf Test Server würde ich gerne anstelle ein eigenen /56 Subnetz verwenden. Leider scheint es nicht zu funktionnieren.
Soll anstelle 2a03:2260:xyz::/48 auf alle Server ein /56 Subnetz deklariert werden, oder reicht es aus wenn ich nur aud der Test GW ein /56 Netz deklariere.
Hi,
es kommt auch darauf an, was die Router announcen. Bei uns funktioniert das mit /56 eigentlich.
Viele Grüße
Matthias
@MPW Die offiziellen Server „annoucen“ alle der /48 Netz. Ich nehme an dass die bereits vorhandene Gateways anstelle einer /48 ein /52 melden sollten wenn wir bis zu 8 GW mit eigenen Subnetz betreiben wollen. Ist es richtig so?
Ich verstehe nicht so richtig, was ihr vorhabt. Wir haben pro Gateway mehrere Domänen und jede hat ein eigenes /56. Diese werden richtung FFRL alle separat gemeldet.
Wir haben zur Zeit 3 GW, alle 3 melden das /48 Subnetz. Ich denke, dass es besser wäre jeder GW ein Teil nur des /48 Subnetz zu bedienen. Zur Zeit stehen 2 weitere GW zur Verfügung die Für interne Tests verwendet werden, u.a. l2tp. Dies stellt uns (mit) die Möglichkeit einiges zu verifizieren. Ich bin jemanden der der Aufbau des Netzes eher aus theoretische Standpunkt betrachte und auch überlegt was besser gemacht werden könnte.
Auf die Test GW habe ich keine IPv6 Verbindung, des heißt dass der Zugang zum AS wie ein Mülleimer wirkt, er wird gefüttert, zurück kommt nicht. Es geht mir primär darum die IPv6 Konnektivität auf die Test Server zu erhalten und danach fundierte Vorschläge für eine besseren Aufbau unsere Netz auszuarbeiten.
Mit BGP habe ich nicht so viele Erfahrungen (keine), vom Netzwerk Verkehr außerhalb einen Rechenzentrum ein wenig mehr.
PS:
Ich bin nicht der Admin Bzw. ich will es nicht sein, auch wen ich root Zugriff auf alle GW habe. Test, Debuggen und Theorie reichen aus, um die wenige Zeit die ich habe, zu belegen. Ich Überlege wie Unzulänglichkeiten die ich feststelle optimal eliminiert werden können.
Jo, man kann es direkter leiten, wenn man die Teilnetze einzeln anmeldet.
Es muß nicht nur lokal konfiguriert werden, sondern auch per BGP announciert gen FFRL; more specific sticht, d. h. wenn Ihr 2a03:2260:cafe::/48 von allen »normalen« Routern über die FFRL-Tunnel per BGP announciert, und über die Tunnel des Testservers zum FFRL 2a03:2260:cafe:100::/56, dann sollte(!) diese Route für entsprechenden Verkehr beim FFRL bevorzugt werden. (Rein formal sollte aber von den »normalen« Routern auch noch eine Verbindung zum Testserver bestehen und 2a03:2260:cafe:100::/56 annouciert werden, denn mit dem /48 signalisierst Du ja, daß alle Adressen dorthin können. Falls das nicht gewünscht ist, wären /56er in der Tat besser. Eigentlich /64, aber unter /56 routet FFRL ja nicht, unter /48 „das Internet“ nicht.)
Nunja, da sind wir dann auch wieder bei den Begrifflichkeiten. ‚Supernode‘ ist für mich zumindest was anderes als ein ‚Gateway‘. Ich klebe mal unsere letzte Planung rein:
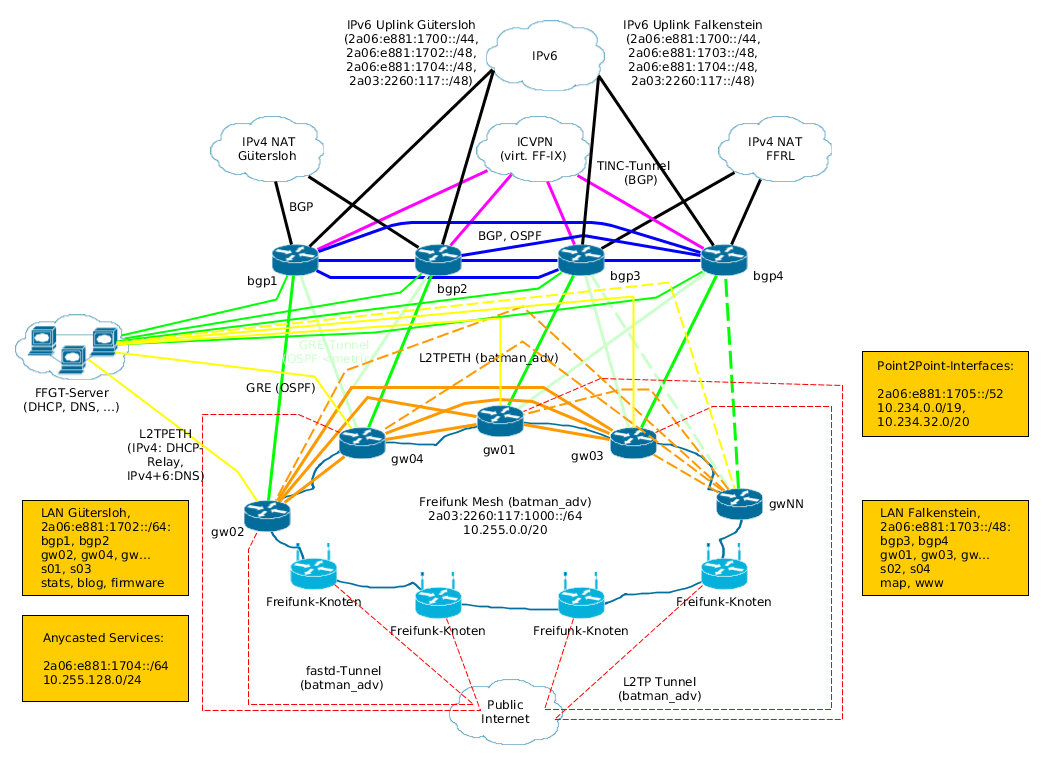
Auf der Ebene der BGP sprechenden VMs geschieht das Außenrouting von/zu unserem AS, das sind wohl Eure ‚Supernodes‘? Unsere ‚Gateways‘ nehmen nur fastd/l2tp an, ziehen das Mesh auf und routen im Grunde ‚default‘ an den (per OSPF bestimmten) ‚nächsten‘ Borderrouter. Im Mesh verwenden wir ein /64 aus dem /48 vom FFRL (was momentan auch nur gen FFRL announced wird; alle Uplinks sind z. Zt. Tunnel); eigentlich wollten wir ein (/47) PI nehmen, aber aus $Gründen (RIPE-Policy, fehlende jur. Person; machte schon die AS-Zuteilung zäh) liegt das auf Eis und wir stellen für die Infrastruktur vom ‚eigenen‘ /44-Fremd-PA auf das ‚eigene‘ /44-PA vom Förderverein um.
Was nicht funktioniert ist, das für ein Mesh jedes gw (bei uns i. d. R. zwei oder vier pro Mesh; andere nennen das dann wohl »Domäne«) ein anderes /64 nutzt; es macht meinem Verständnis nach zumindest keinen großen Sinn, mehrere öffentliche v6-Netze in einem Mesh zu verwenden (der Client wird fast immer über »das erste« Defaultgateway rausgehen).
HTH.
2 „Gefällt mir“
Ich habe mir ein wenig mit bgp befasst, ein wenig undurchsichtig bleibt es aber. Wir verwenden quagga und nicht bird/bird6. Ich konnte unsere Admins nicht dazu bewegen von quagga auf bird umzusteigen.
Die bgpd.conf Dateien der 2 Test Server habe ich angepasst, auch /etc/network/interfaces und /etc/radvd.conf. Für jeder Server habe in ein eigener /52 Subnetz.
Damit erhalten die Clients 2 IPv6 Adressen. Wo die Reise führt kann mit traceroute6 -n www.google.com betrachtet werden, meistens führt der Weg zur GW1 der mit GW2 sich austauscht und schliesslich FF-RL die frohe Botschaft verkündet.
Durch das installieren von radv-filterd sollte der Weg zu passenden GW führen und gleich FF-RL weitergereicht werden. Durch die passende Adresse (IPv6) ist sichergestellt, dass der Rückweg auch ohne Umwege der Client erreicht.
Sollten nach ein Wechsel des GW älttere Verbindungen noch bestehen, bemüht batman der passenden Server. Irgendwann wird die alte IPv6 Route als deprecated markiert und ein weiteren Traffic über Umwege sollte verschwinden.
Zwischen der GW sind ibgp und ospf Verbindungen vorhanden, diese scheinen mir erstmal zwecklos zu sein. Ich muss noch in die Untiefen von ospf tauchen.
Das Ursprüngliche Gedanke war es per BGP je Server 2 präfixen zu announcen, der /48 und der /5[26], Damit hätten wir eine weiterer redundanten Weg gehabt. Da Batman zwischen den Subnetze vermittelt, kommt es nicht zu eine Weiterleitung der Nachrichten über das Layer 3 Tunnel zwischen der GW (Ich habe ospf6d nicht abgefasst).
PS:
Im Hinblick auf viele IPv6 Adressen bei der Clients hatte ich überlegt die von Radvd gemeldete Routen usw. zu priorisieren. (Pref der „störenden“ GW aud low setzen). Dies geht leicht über ein nf_filter Filter. Um mit minimaler Aufwand der GW heraus zu finden reicht ein Zugriff auf der Ausgabe von batctl gwl oder das debug file system. Vorraussetzung ist lediglich eine saubere Vergabe der Mac Adressen auf die Servers.