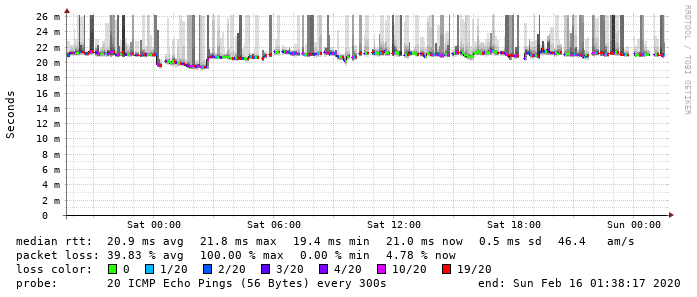
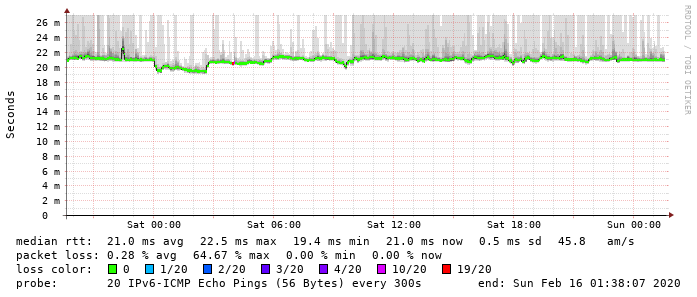
Moin,
folgendes Setup: 4 Gateway-VMs bei einem Hoster, aufgesetzt nach Münsteraner Art, GW 1 und 2 beherrbergen die L2TP-Domänen 1 und 2 parallel, GW 3 und 4 sind dementsprechend für die Domänen 3 und 4 zuständig. Sprich: 2 v15 batman-Interfaces je GW.
Symptom: Nutzer melden, daß „gar nix mehr geht“, heißt nach eigenen Tests: IPv4 in einer Domäne tut plötzlich nicht/nur sporadisch, obwohl IPv6 geht. Die andere Domäne auf den gleichen GWs ist davon nach aktuellem Kenntnisstand nicht betroffen.
Zum Debuggen haben wir nun (bei einem anderen Hoster) 4 VMs aufgesetzt, jeweils ein Gluon-x86 vor einer Linux-VM, Gluon-VM geht per virbr0 & NAT zu den Gateways, Linux-VM hängt in privater Bridge mit dem „LAN“ des Gluon-VM:
br-tst1 8000.fe00c5e342fb no one-305-0
one-306-1
br-tst2 8000.fe009eaff856 no one-307-0
one-308-1
virbr0 8000.5254003b6c4d yes one-305-1
one-306-0
one-307-1
one-308-0
virbr0-nic
Pärchen 1 (VM one-305 & one-306) ist in Domäne 3, der mit den Problemen, Pärchen 2 (VM one-307 & one-308) in Domäne 1. Und so stellt sich das Problem dar (v6-IPs auf Doku-Prefix „anonymisiert“).
root@testvm01:~# ip route | grep defa
default via 10.15.32.4 dev ens4
root@testvm01:~# (LANG=C date ; ((ping -c 5 10.15.32.4)&) ; ((ping -6 -c 5 2001:db8:2004:333::4)&) ; echo)
Mi 12. Feb 18:31:15 CET 2020
PING 2001:db8:2004:333::4(2001:db8:2004:333::4) 56 data bytes
64 bytes from 2001:db8:2004:333::4: icmp_seq=1 ttl=64 time=2.85 ms
64 bytes from 2001:db8:2004:333::4: icmp_seq=2 ttl=64 time=2.82 ms
64 bytes from 2001:db8:2004:333::4: icmp_seq=3 ttl=64 time=3.19 ms
64 bytes from 2001:db8:2004:333::4: icmp_seq=4 ttl=64 time=2.84 ms
64 bytes from 2001:db8:2004:333::4: icmp_seq=5 ttl=64 time=3.11 ms
--- 2001:db8:2004:333::4 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4006ms
rtt min/avg/max/mdev = 2.828/2.967/3.196/0.155 ms
PING 10.15.32.4 (10.15.32.4) 56(84) bytes of data.
--- 10.15.32.4 ping statistics ---
5 packets transmitted, 0 received, 100% packet loss, time 4102ms
root@gw03 ~ # ip -4 addr show bat03
3: bat03: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
inet 10.15.32.4/20 brd 10.15.47.255 scope global bat03
valid_lft forever preferred_lft forever
root@gw03 ~ # (LANG=C date ; ((ping -c 5 10.15.36.95)&) ; ((ping6 -c 5 2001:db8:2004:333:0:c5ff:fee3:42fc)&) ; echo)
Mi 12. Feb 18:31:15 CET 2020
PING 2001:db8:2004:333:0:c5ff:fee3:42fc(2001:db8:2004:333:0:c5ff:fee3:42fc) 56 data bytes
64 bytes from 2001:db8:2004:333:0:c5ff:fee3:42fc: icmp_seq=1 ttl=64 time=2.94 ms
64 bytes from 2001:db8:2004:333:0:c5ff:fee3:42fc: icmp_seq=2 ttl=64 time=3.02 ms
64 bytes from 2001:db8:2004:333:0:c5ff:fee3:42fc: icmp_seq=3 ttl=64 time=3.10 ms
64 bytes from 2001:db8:2004:333:0:c5ff:fee3:42fc: icmp_seq=4 ttl=64 time=3.00 ms
64 bytes from 2001:db8:2004:333:0:c5ff:fee3:42fc: icmp_seq=5 ttl=64 time=2.92 ms
--- 2001:db8:2004:333:0:c5ff:fee3:42fc ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4003ms
rtt min/avg/max/mdev = 2.929/3.001/3.106/0.063 ms
PING 10.15.36.95 (10.15.36.95) 56(84) bytes of data.
--- 10.15.36.95 ping statistics ---
5 packets transmitted, 0 received, 100% packet loss, time 4101ms
Ich. Versteh’s. Nicht. Habe ich so auch noch nicht gesehen, und daß v6 tut und v4 nicht spricht auch gegen karpottes batman? Anyway, any ideas?