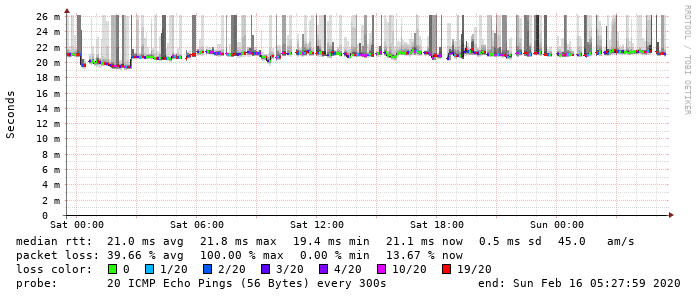
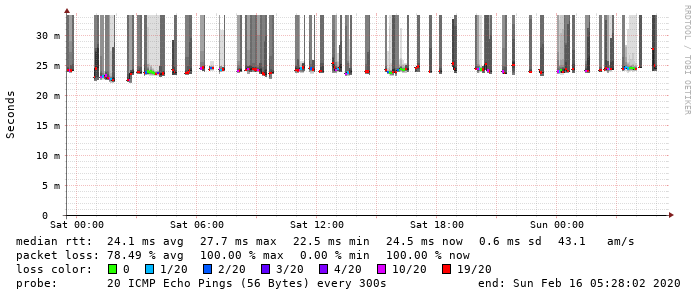
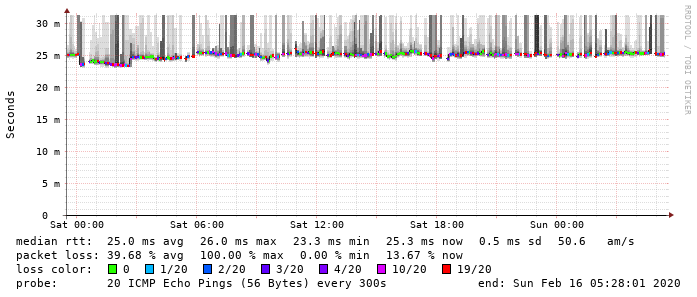
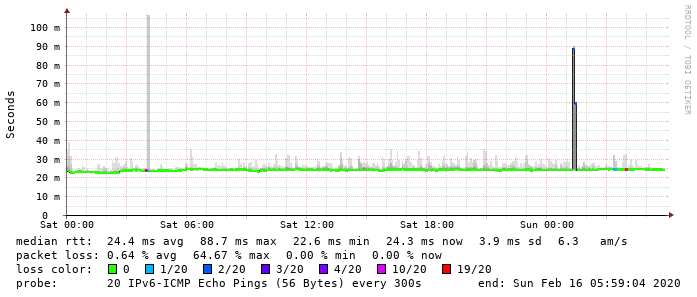
Da beide Seiten, Linux-VM hinter Gluon-VM an GW03 als auch RPi hinter WNDRMACv2 an GW03 (GW04 ist z. Zt. abgeschaltet) jeweils Probleme haben, ist da Ergebnis wenig überraschen noch schlechter.
Wie findet man heraus, warum? Wie verhindert man das? Und wieso zum Henker kann Batman Advanced nur für v4 karpott sein? Ich weiß, daß batman-adv.ko an DHCP rumspielt. Aber wenn v4, aber nicht v6, karpott ist, müßte es ja ARP sein, was nicht weitergeleitet wird‽ Und wieso betrifft es standfest nur 1 von 2 „Domänen“, was ist an D3 so anders, daß dort batman-adv ins Essen bricht, nicht aber (auch) bei der parallel auf dem GW laufenden D4?
Sun Feb 16 05:57:05 CET 2020
traceroute to 02:00:c5:e3:42:fc (16:f1:a2:ab:4e:eb), 50 hops max, 20 byte packets
1: 02:ca:ff:ee:03:04 20.368 ms 20.369 ms 20.439 ms
2: 16:f1:a2:ab:4e:eb 63.998 ms 23.362 ms 23.004 ms
Läuft in einer while-Schleife, bislang (und wann immer ich das schon mal geguckt habe) war das unauffällig, ja.
Ähnlich wie die v6-Tests, hier RPI hinter WNDRMACv2 an GW03 zu Linux-VM hinter Gluon-VM an GW03:
Falls das Problem noch besteht: Hat es eventuell mit dem IPv4 Connection Tracking zu tun? Wird für NAT gebraucht, betrifft deshalb wahrscheinlich nur Verbindungen nach Außen, wenn das GW selbst auch NATed auf einem Virtualisierungshost, z.B. Proxmox ist, natürlich auch den Host.
Wir haben hier den sysctl
net.netfilter.nf_conntrack_max=1000000
gesetzt und in dem Dunstkreis der Vollständigkeit halber auch noch:
net.netfilter.nf_conntrack_acct=1
net.netfilter.nf_conntrack_checksum=0
net.netfilter.nf_conntrack_tcp_timeout_established=7440
net.netfilter.nf_conntrack_udp_timeout=60
net.netfilter.nf_conntrack_udp_timeout_stream=180
Nein, das ist es nicht.
(Wenngleich das auch ein tolles Fehlerszenario ist, auch schon häufiger gesehen bei „Communities, die glauben, kein Monitoriing zu brauchen“)
Du siehst: Auch die interne (private) IPv4 des Gateways von dem Packetloss betroffen ist. Also noch „vor dem NAT“.
Es geht ja nichtmal "zwischen den lokalen IPv4-Adressen an verschiedenen Knoten der gleichen Domain!
Problem konnte nicht gelöst werden und da »Produktivnetz«, durch Separation (Single-Mesh-GWs) und Neuaufbau, erschlagen. Bitte weitergehen, hier gibt’s nichts mehr zu sehen.
Kannst du da vielleicht nochmal ein bisschen darauf eingehen, evtl. in einem neuen Thread?
Welches Problem löst du indem du die beiden UDP timeouts erhöhst (default ist 30 und 120 respektive)?
Wie nutzt du die Flow Accounting Informationen, die du da aktivierst?
Also wenn es euch hilft: Wir hatten es in „Neanderfunk-Mettmann“ auch gerade… und haben es durch Supernode-Powercycle (und damit downgrade auf batman 2017.4) erstmal behoben.
Aber uns nicht klar, ob das nur temporär war.