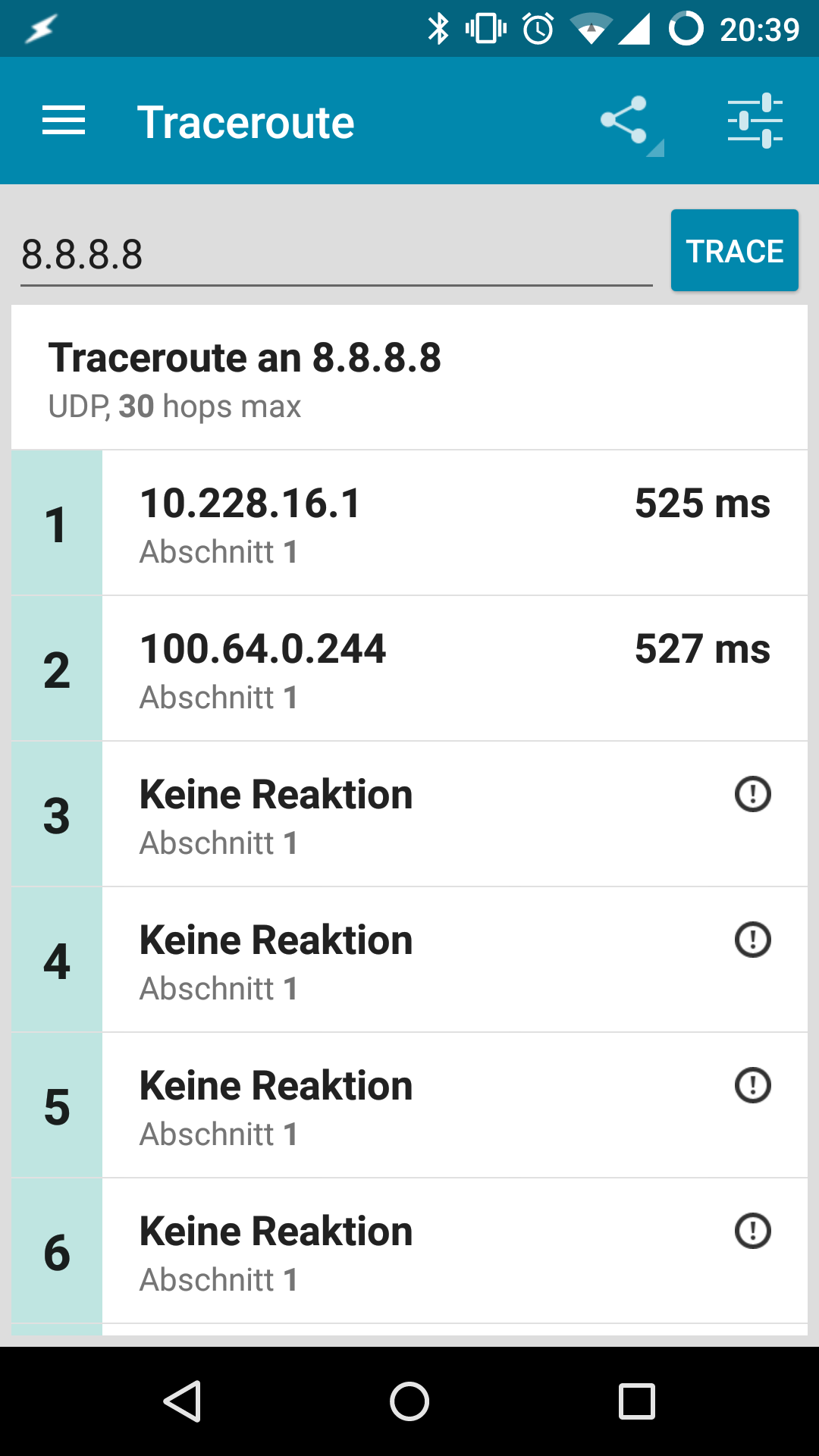
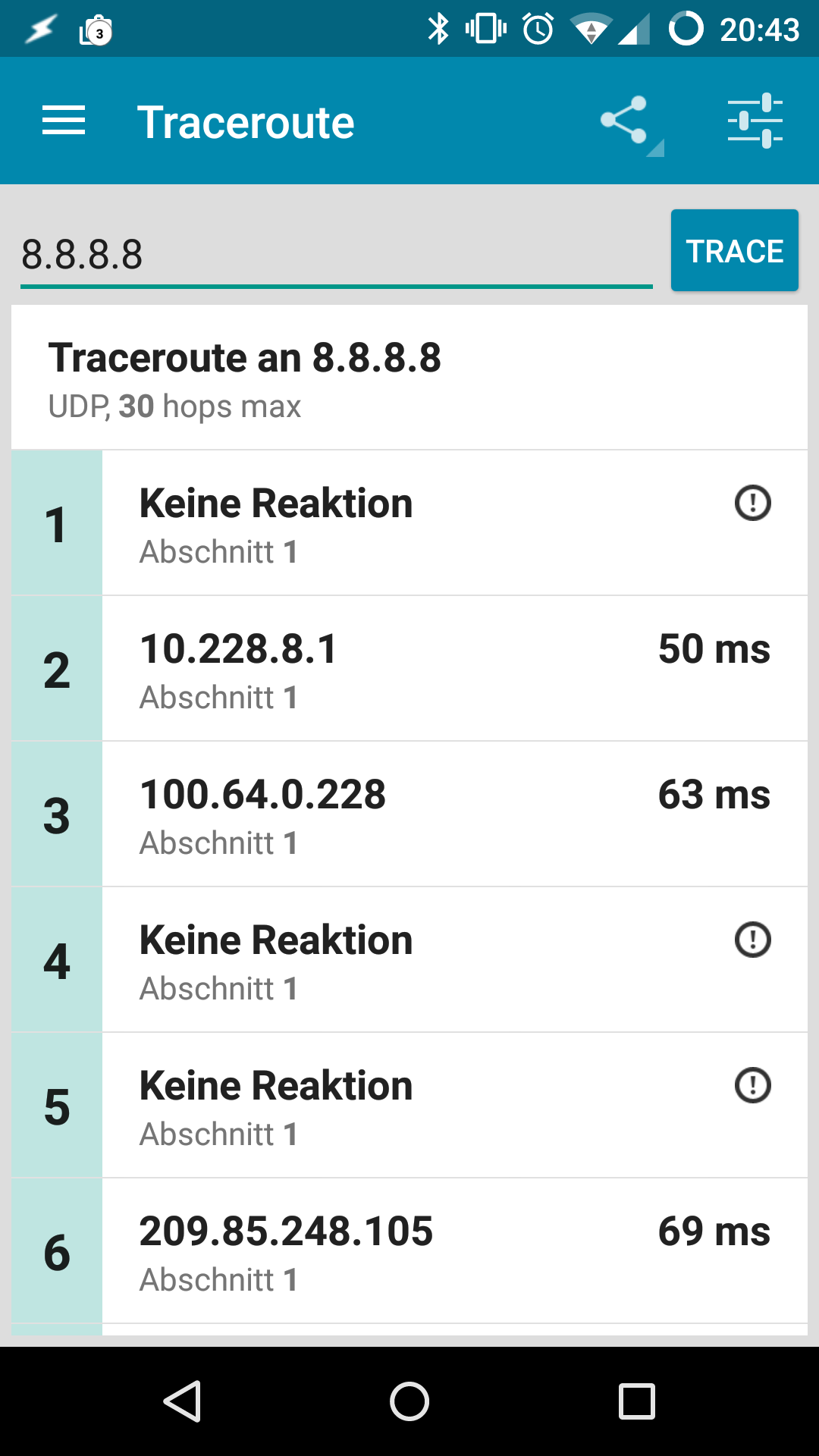
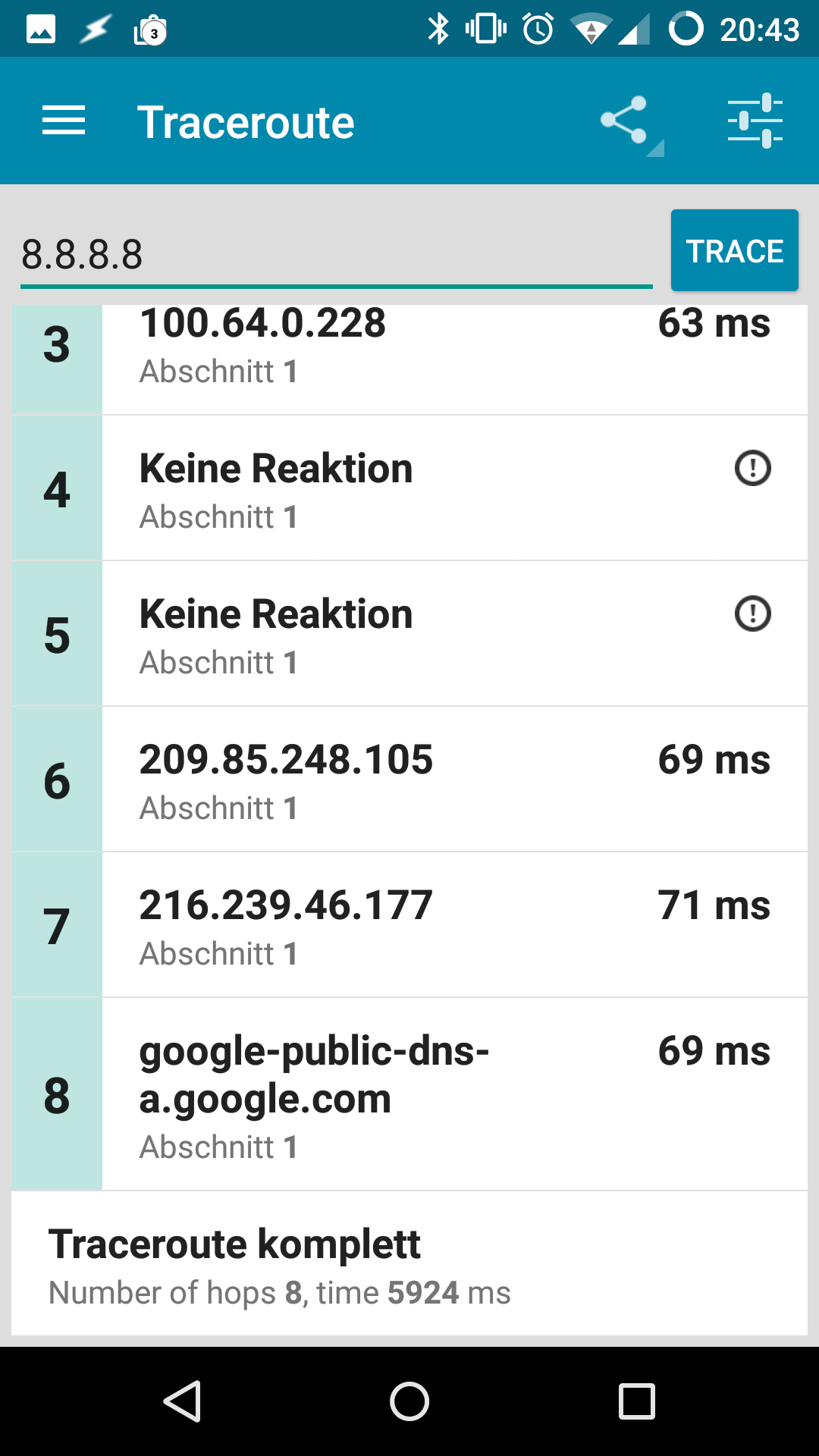
Also die Fehlerbeschreibung kann ich für die von mir betreuten Standorte weiterhin aufrecht erhalten. Endgeräte kommen regelmäßig nur nach einem reboot der FF-Knoten ins Netz. Im fehlerhaften Zustand sind meistens gar keine oder nur 1 supernode aus dem FF Client Netz zu erreichen. Die Knoten sind jedoch durchgängig auf der Karte mit Clients sichtbar.
Nach einem Reboot funktioniert dann erst einmal wieder „alles“. (Auch nach dem reboot geht z.B. Google Play nicht, aber das ist ein anderes Thema, siehe hier im Forum)
Nach 2 Wochen ist das Bild unverändert. Da das Problem anscheinend nur bei mir existiert bin ich erstmal raus hier und beobachte die FF-E Entwicklung passiv weiter.
Falls sich das Problem dennoch bei jemandem zeigt nutzen vielleicht folgende 2 traceroutes:
Ein fehlerhafter uplink liefert diesen traceroute:
Ich denke, das ich das gleiche Problem habe. Ich kann über freifunk die internen Dienste, wie das Forum und den Meshviewer erreichen, aber nux im Internet.
Mein Traceroute sieht so wie oben beschrieben aus:
VPN status
fastd running for 151620.532 seconds
There are 4 peers configured, of which 2 are connected:
mesh_vpn_backbone_1_peer_node02: not connected
mesh_vpn_backbone_1_peer_node01: connected for 151578.673 seconds
mesh_vpn_backbone_2_peer_node01: not connected
mesh_vpn_backbone_2_peer_node02: connected for 151580.017 seconds
Wir werden sowieso bei der neuen Gluon-Version nur noch einen VPN-Tunnel einsetzen. Das wird schon mal etwas weniger Probleme bringen.
Ich glaube nicht, dass das in Ordnung ist. Mein Router ist mit der 10.228.24.1er Supernode verbunden. route zeigt mir an, dass mein default gateway 10.228.24.1 ist. Soweit alles super.
Jetzt mache ich mal ein Ping auf 8.8.8.8 und bekomme:
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
From 10.228.24.1: icmp_seq=1 Redirect Host(New nexthop: 10.228.8.1)
64 bytes from 8.8.8.8: icmp_seq=1 ttl=56 time=305 ms
Also habe ich einen ICMP-Redirect bekommen auf 10.228.8.1. Das heißt hier leitet jetzt die Supernode nochmal durch nen GRE-Tunnel zur anderen Supernode und von dahin erst ins restliche Rheinland-AS.
Das erste was ich vermutet hatte war, dass die BATMAN gateway selection möglicherweise diese ICMP-redirects verursacht und durch ein Update von BATMAN auf den Supernodes jetzt die Funktion aktiviert worden ist.
Das könnte aber sinnvoll sein und damit nichts zu tun haben, wenn zum Beispiel die 10.228.8.1-Supernode im gleichen Rechenzentrum steht, wie die Rheinland-Infrastruktur, aber ist für mich jetzt erst mal unwahrscheinlich. Soweit ich weiß bei BGP jedoch eine mögliche Konfigurationsmöglichkeit.
@pberndro Weißt du woran das liegt? Könnte ja ein Bottleneck sein, wenn es so nicht sein soll… Könnte da vielleicht BIRD bei der 10.228.24.1 Supernode Probleme mit der Verbindung zur Rheinland-Infrastruktur haben? Also nur BIRD könnte außer BATMAN ICMP-redirects verschicken.
@anon88999732,
ich wollte nicht sagen, dass das routen über 2 Supernodes ok ist, sondern nur, das es immer noch besser ist als gar keine Verbindung.
Wenn das Routing an der Stelle durch BGP erfolgt kann man sicher das Routing gerade ziehen. BGP ist ja genau dazu designed, die Routen mit Hilfe manuell eingestellter Parameter festzulegen.
Eine mögliche Fehlerquelle kann uebrigens einfach ein asynchrones Routing sein, dh, in die eine Richtung wird ein anderer Weg genommen als in der anderen. Ich habe null Ahnung von dem Setup der Supernodes, abe genau sowas hab ich schon öfter erlebt.
@oldman
Ich wundere mich die ganze Zeit wie das BATMAN der Supernodes konfiguriert ist. Hat jede Supernode einen eigenen DHCP-Server oder teilen sich alle einen? Sinnvoll wäre ja, dass jede einen eigenen hat (was ich auch die ganze Zeit schon angenommen habe). Dann sollte ja eigentlich, wenn die Supernodes per GRE/BGP miteinander verbunden sind der Gateway client mode statt dem Server mode benutzt werden, aber ich habe letztens irgendwo ein Diagramm oder so mit der announced bandwidth der Supernodes gesehen und das funktioniert eigentlich ja nur mit dem Gateway server mode…
Ich rede/schreibe jetzt mal ins Blaue, aber wenn jede Supernode einen eigenen DHCP Server hat, und zwei Uplink-Knoten aus einem gemeinsamen Mesch mit zwei unterschiedlichen Supernodes verbinden, haette man zwei verschiedene IP Ranges im gleichen Netz.
Was sagt denn batctl gw_mode?
Es gibt den Gateway-Mode „Client“ und „Server“. Der Unterschied ist, dass bei dem „Server“-Mode nicht BATMAN entscheidet, welche Gateway benutzt wird, sondern alle DHCP-Requests gebroadcastet werden und die Clients sich für ein Gateway entscheiden. Beim „Client“-Modus hingegen kann BATMAN die DHCP-Requests manipulieren und sie an die beste Verbindung weiterleiten. Den „Client“-Modus kann man auch so einstellen, dass immer die Gateway der Supernode, zu der man verbunden ist bevorzugt wird. Der Vorteil ist halt auch, dass die DHCP-Requests nicht an alle Supernodes gebroadcastet werden…
wir hatten das mehrfach: einmal waren uns schlicht die dhcp leases ausgegangen … das andere mal verabschiedete sich die tunnel auf den sn, die haben aber sich weiter munter als gw announced, also eher kein router/fehler - richtig gefunden haben wir den fehler nicht, manchmal killt alfred -m auf schwachen geräten (bzw. stirbt ohne zu sterben, das ja das ärgerliche …antwortet schlicht nicht mehr obwohls noch läuft - so gesehen mind. auf dem raspberry pi)
Bei IPv4 können auch die Contrack-Buffer ausgehen…
Effekt ist dann meist „Nach Plasterouter-Neustart geht es erstmal wieder“ → Freifunkende denken „Mein Router war abgestürzt“
Und je nach Charakterstärke der Admins werden $NUTZENDE auch bei dem Glauben belassen.
Du denkst zu sehr in Layer 3 und Subnetzen. Es ist aber ein Layer 2-Netz über alle Supernodes.
Der Router verbindet sich zwar mit einem oder mehreren Servern über FastD, damit ist er aber erst mal nur Teilnehmer im Layer 2-Netz. Das wäre als wenn du deinen PC einfach mit dem Netzwerk verbindest, aber keinerlei IP-Konfiguration (auch kein DHCP) vornimmst.
Nach der Verbindung sendet der Router DHCP-Broadcasts. Die sehen aber nicht alle Supernodes, denn BATMAN steuert, welches Gateway verwendet werden soll und auch nur dieses Gateway bekommt den DHCP-Request. Danach erhält der Router von dieser einen Supernode eine IP-Adresse. Nicht von mehreren.
Da diese IP-Adresse - wie du ja selber schon schreibst - nur aus einem gesonderten Bereich, aber nicht aus einem getrennten Subnetz ist, kann er sie auch weiter nutzen, wenn BATMAN auf die Idee kommen sollte, ein anderes Gateway zu bevorzugen. Es ist eben EIN Netz, in dem jeder DHCP-Server aus einem bestimmten Bereich (NICHT Subnetz) Adressen verteilt.