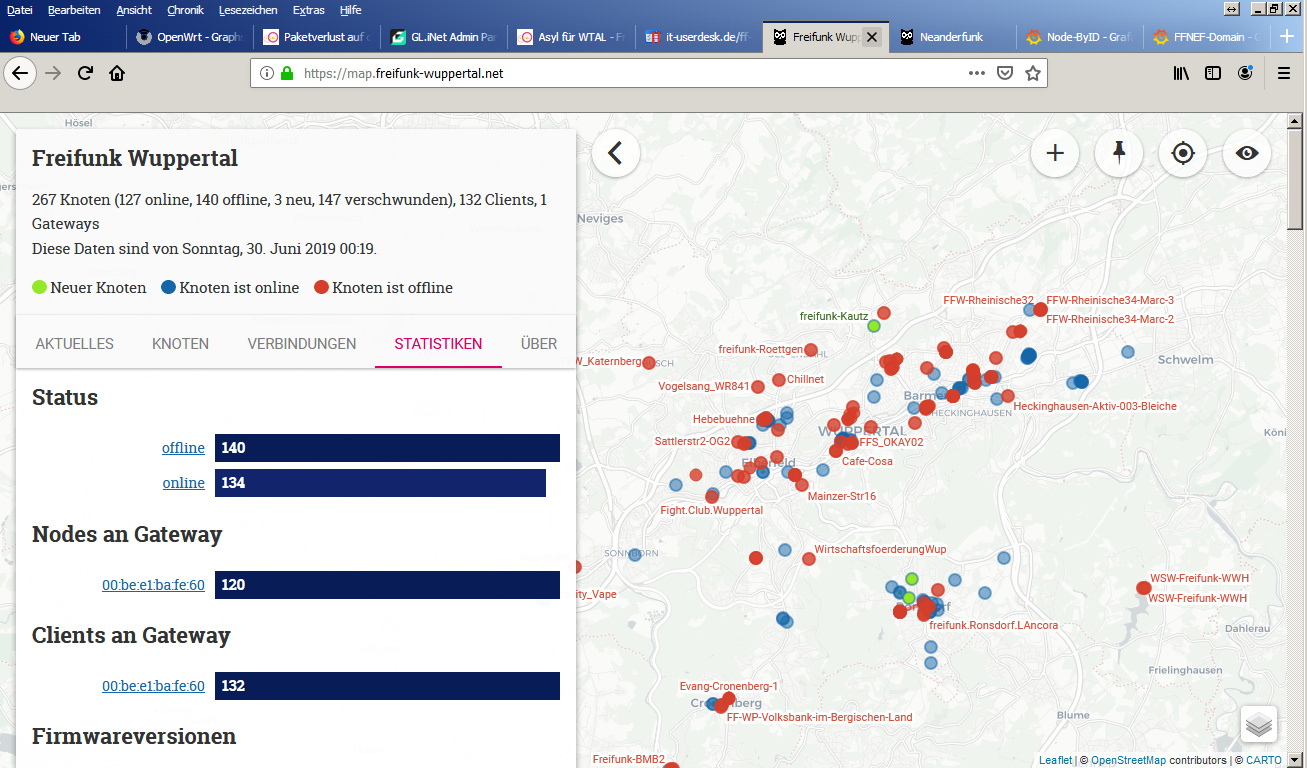
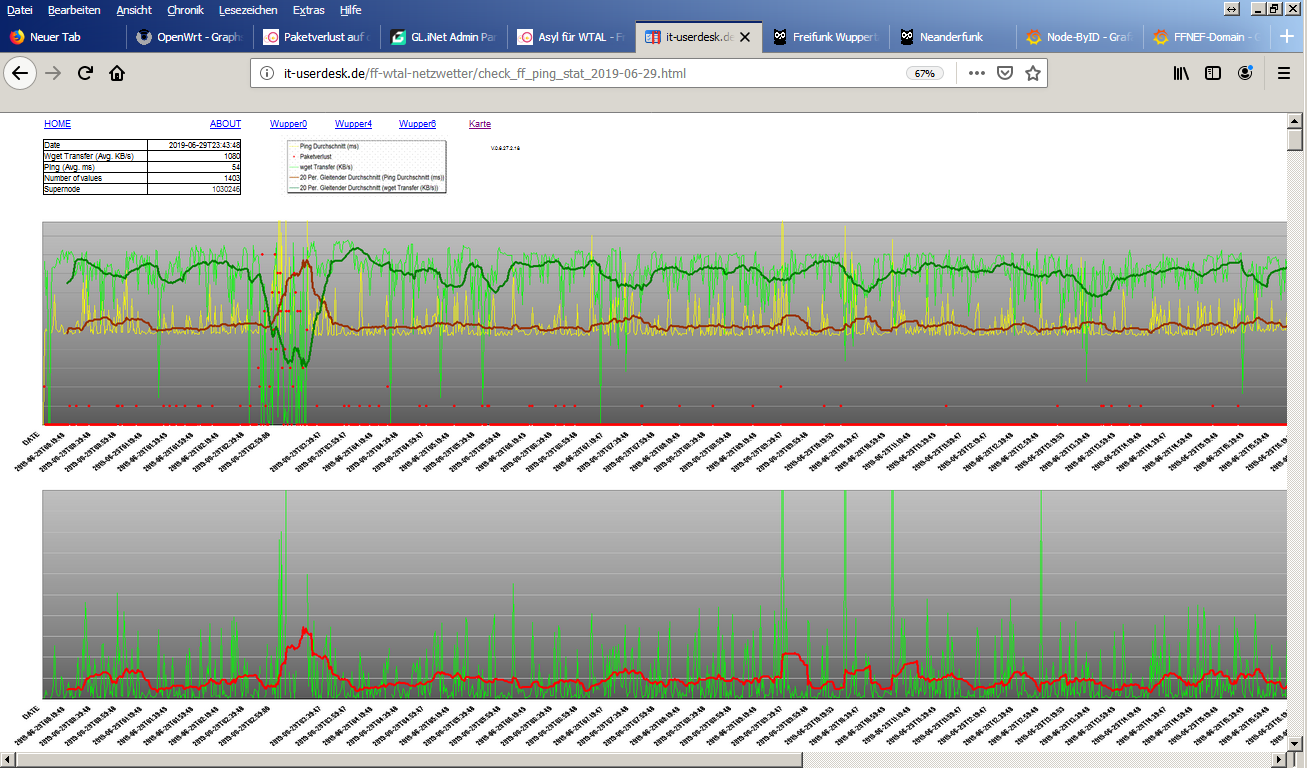
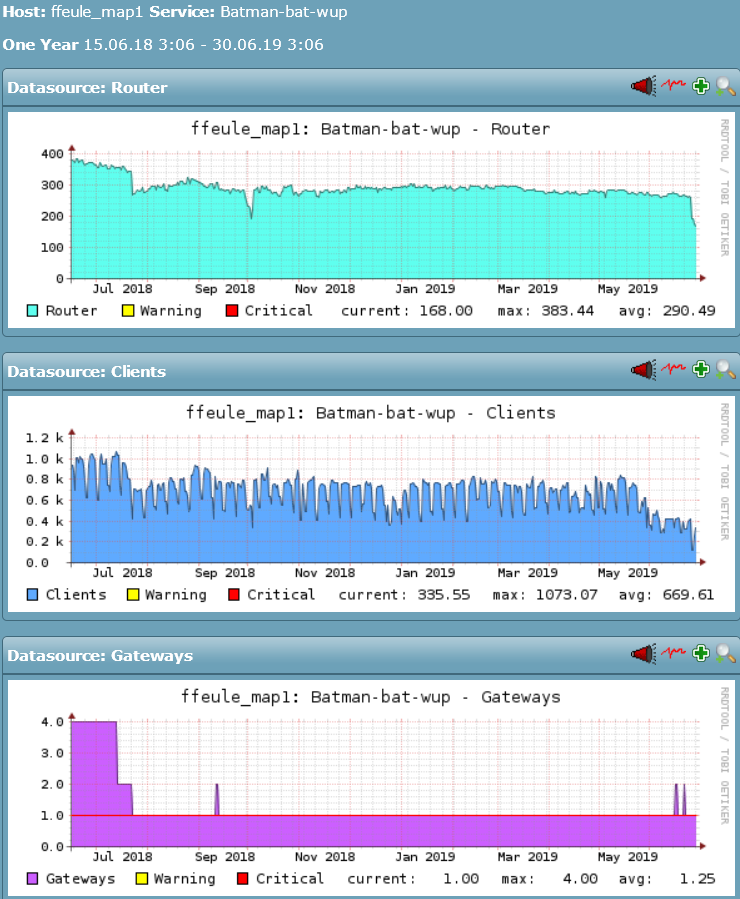
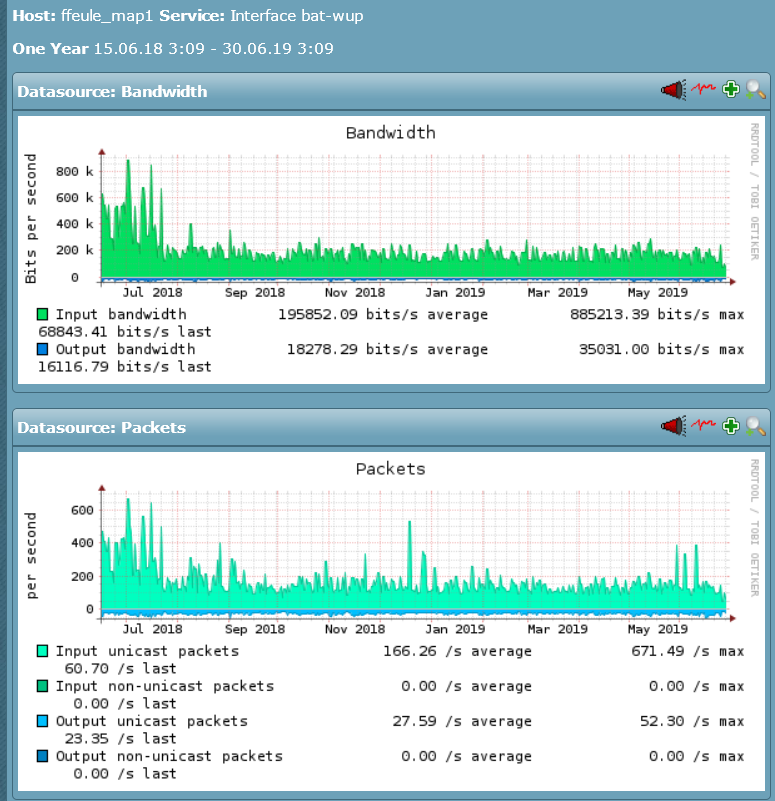
Hallo zusammen,
seit Anfang des Monats erleben wir heftige Paketverluste auf den VMs. Die VM selbst ist nicht nennenswert ausgelastet. Wie sieht die Leitung aus?
My traceroute [v0.92]
xxxxxx (xxxxxxxxxxxxx) 2019-06-16T23:26:47+0200
Keys: Help Display mode Restart statistics Order of fields quit
Last 200 pings
1. xxxxxxxxxxxxxxxxxxxxxxxx ........................................................................................................................................................................................................
2. xxxxxxxxxxxxxxxxxxxxxxxx ........................................................................................................................................................................................................
3. xxxxxxxxxxxx ........................................................................................................................................................................................................
4. xxxxxxxxxxx ........................................................................................................................................................................................................
5. xxxxxxxxxxxxxx ........................................................................................................................................................................................................
6. xxxxxxxxxxxxx .......................................................................................................................................................................................................
7. xe-2-0-0-501.bno1-r1.sys .......................................................................................................................................................................................................
8. ae8-0.blu1-r2.syseleven. .......................................................................................................................................................................................................
9. ae2-0.bak1-r1.syseleven. .......................................................................................................................................................................................................
10. 185-46-137-93.syseleven. .......................................................................................................................................................................................................
11. 185-46-137-139.syseleven .....................??????????????????????..?????????????..>.?...........................................?????..??????????????????????..???...................???...........................??........
Scale: .:14 ms 1:55 ms 2:124 ms 3:220 ms a:343 ms b:494 ms c:673 ms >
bitte teilt uns mit, wenn die Kisten überbelegt wurden. Natürlich wäre es schön zu erfahren, wenn es andere Gründe für den Paketverlust gibt. Hier noch eine Ausgabe der Zusammenfassung:
My traceroute [v0.92]
xxxxxx (xxxxxxxxxxxxx) 2019-06-16T23:41:55+0200
Keys: Help Display mode Restart statistics Order of fields quit
Packets Pings
Host Loss% Snt Last Avg Best Wrst StDev
1. xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx 0.0% 1115 1.8 1.2 0.7 17.2 0.8
2. xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx 0.0% 1114 8.5 9.1 8.1 55.9 1.7
3. xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx 0.0% 1114 9.2 9.2 8.2 17.8 0.8
4. xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx 0.0% 1114 12.5 12.1 11.1 18.6 0.6
5. xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx 0.0% 1114 11.6 12.0 10.6 46.4 2.7
6. xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx 0.0% 1114 20.6 20.3 19.2 69.6 1.6
7. xe-2-0-0-501.bno1-r1.syseleven.net 0.0% 1114 31.8 32.5 30.9 75.9 2.1
8. ae8-0.blu1-r2.syseleven.net 0.0% 1114 32.8 33.4 31.7 86.3 2.6
9. ae2-0.bak1-r1.syseleven.net 0.0% 1114 33.1 32.6 31.3 81.1 2.2
10. 185-46-137-93.syseleven.net 0.0% 1114 30.8 30.2 28.9 105.7 2.9
11. 185-46-137-139.syseleven.net 32.1% 1114 31.9 32.6 30.0 879.3 30.9
Danke und viele Grüße
phip