Für Rhein-Sieg wurde vor kurzem neuer Map-Server/Statistik-Server aufgesetzt
Ansible Rollen im Rhein-Sieg github
Schema:
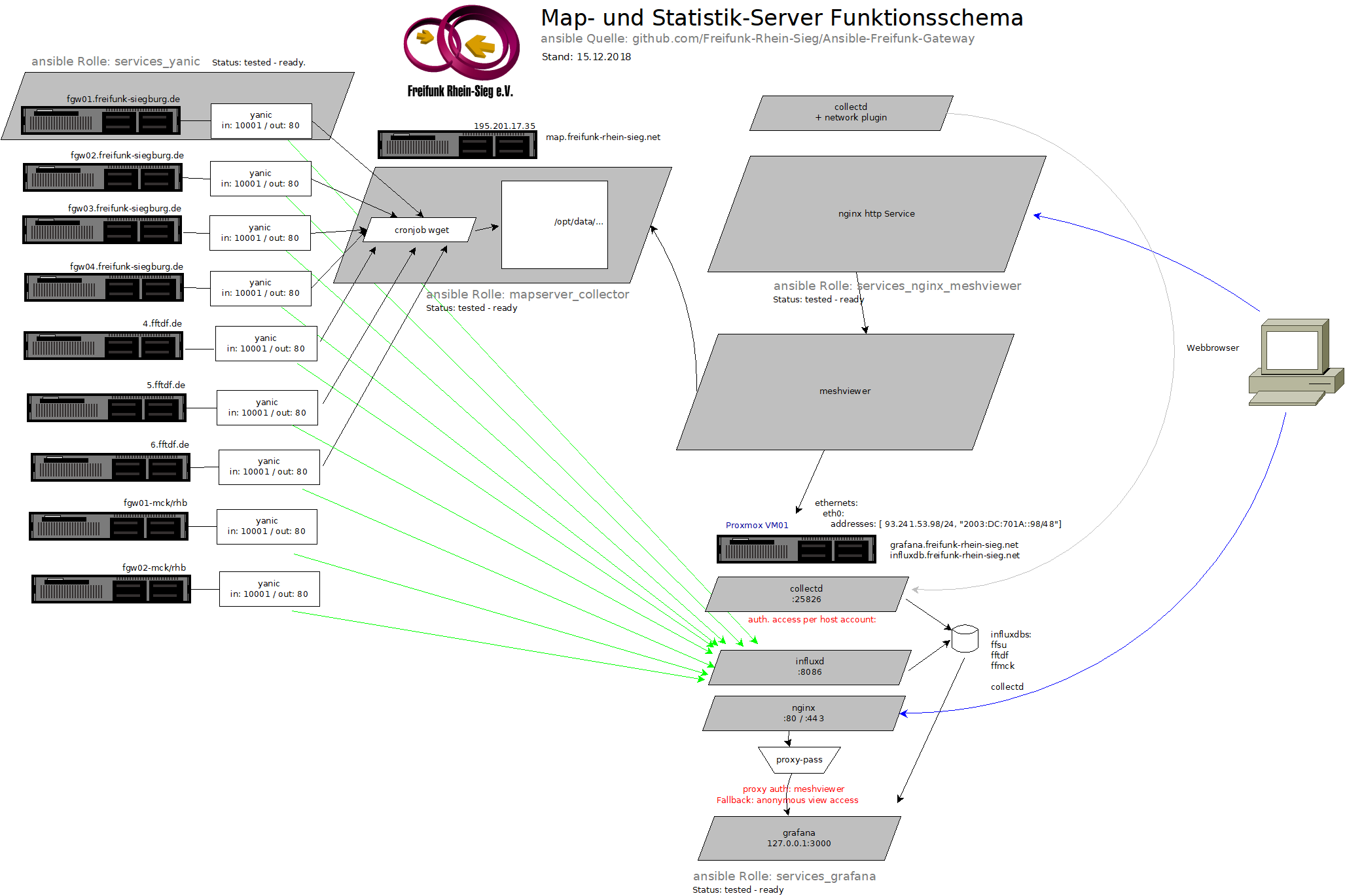
Multidomain-Gateways setups kurz im Admin-Tagebuch beschrieben
Für Rhein-Sieg wurde vor kurzem neuer Map-Server/Statistik-Server aufgesetzt
Ansible Rollen im Rhein-Sieg github
Schema:
Multidomain-Gateways setups kurz im Admin-Tagebuch beschrieben