Die bekomme ich
eigentlich überall:
[906502.390000] ath: phy0: Failed to stop TX DMA,
queues=0x00c!
[934357.890000] ath: phy0: Failed to stop TX DMA,
queues=0x004!
[952429.080000] ath: phy0: Failed to stop TX DMA,
queues=0x004!
[963144.140000] ath: phy0: Failed to stop TX DMA,
queues=0x004!
[1031556.270000] ath: phy0: Failed to stop TX DMA,
queues=0x004!
Die Dinger laufen
aber wunderbar (scheinbar?)
Naja, da ist einiges an Zeit zwischen. 19 Tage zwischen dem letzten und dem vorletzten Eintrag. der erste Eintrag ist nach zehn Tagen Betriebszeit.
Bei uns haben sich die Geräte in aller Regel nach einiger Zeit wieder stabilisiert und dann wieder normal funktioniert. Mal nach Minuten, mal nach Stunden.
Wir haben daher den Weg gewählt, die Geräte ganz stumpf grundsätzlich neu zu starten, denn um Zeitpunkt dieser Meldung haben sie sich auf alle Fälle, ich sage jetzt mal verschluckt.
Aber wie gesagt, seit wir Mitte Oktober den Release von Barrier Breaker aufgespielt haben, gab es keinen einzigen Neustart mehr (Unser Skipt schreibt E-Mails und zum Lan hin funktionieren die Geräte noch normal).
Allgemeinen zentralen Syslog wollte ich für die APs nicht, damit könnten wir unsere Bewohner auf der Anlage doch zu genau tracken.
Daher quick and dirty per e-mail:
Ich würde mir an deiner Stelle erstmal nur E-Mails schreiben lassen wenn etwas ist. So hast du die Möglichkeit zeitnah zu testen ob die Geräte funktionieren wie sie sollen.
@nungig
nachdem sich hier alles für mich als viel komplexer als „mach nen ping und gut iss“ herauskristallisiert, würde ich mir ein Statement von dir wünschen.
Was könnte ich deiner Meinung nach noch machen?
Mein Problem ist, dass ich nach wie vor kein Kriterium gefunden habe, nach dem ein Script auf dem Router erkennen könnte, „dass seine Plastebüchse“ ein Problem hat (egal wer jetzt „Schuld“ ist)
Einziges sicheres Kriterium bislang
„kann kein IPv6 jenseits des Gateways erreichen per PING6 oder anderen Protokollen“
Bisher gefundene Abhilfen
Reboot oder
Network restarten
Nun möchte ich aber nicht blind rebooten (oder /etc/init.d/network restart ) ausführen, nur wenn die Aussenanbindung zu google oder heise (oder dem berliner Hoster von www.freifunk.net, you name it) mal für 5 Minuten ausgefallen ist.
(ich könnte auch forum.freifunk.net per IPv6 anpingen… aber würde sich auch false positives erzeugen…)
Sprich: Das alte Leid mit dem hinreichenden Kriterium und den false Positives…
Wann soll die Kiste sich selbst den Resetknopf drücken?
Mein Problem ist, dass offensichtlich entweder nur ich das Problem habe oder andere das alles nicht für ein Problem halten.
Wäre dem nicht so, müsste es doch hier nur so an Ideen rauchen und Lösungsvorschläge auf uns nieder prasseln.
Die Situation stellt sich aber so dar:
X meldet ein Problem
Y und Z erkennen es als Problem an.
Alle anderen - A- W schweigen sich aus - und ich kann nicht wirklich erkennen, dass gemeinsam nach einer Lösung gesucht wird.
Das irritiert mich, weil ich es nicht einordnen kann.
Will man nicht? Kann man nicht? Will man zwar grundsätzlich - aber im speziellen Fall nicht?
Irgendwie ratlos… verbleibe ich und versuche demnächst mal ein paar Grundsatzfragen zu formulieren
Naja ich denke mal: Helfen will hier jeder! Wir verrichten ja alle das gleiche.
Nur wird wahrscheinlich nicht jeder, wie auch ich, dir hier im Thema bescheid geben, dass er es nicht weiß. (Ansonsten würde das Thema ja auch explodieren for Posts ohne eine Lösung gefunden zu haben.) Ist ja auch kein Zwang-Forum. Zwang gibts im Ehrenamt nicht, jeder buttert so viel Freizeit rein wie er möchte.
Klar bleiben Sachen manchmal unbeantwortet, aber ich denke nicht, dass Ignoranz der Grund ist…
Dann gehe ich mal davon aus, dass ein spezielles Gelsenkirchener Problem ist. Und ich leite für mich technisch unbedarft ab, dass es nichts mit den Geräten vor Ort zu tun haben kann (muss) - also eine Instanz darüber verortet werden könnte.
Bleibt aber wieder die Frage, warum nur ich… - ich kann es drehen und wenden - komme aber nicht weiter.
Übrigens sollte ja auch nicht jeder sagen, dass er nicht helfen kann, sondern die, die vermutlich technisch in der Lage wären, das Problem einzugrenzen.
Die Admins, Firmwarebastler, Gluon-Erfinder und was weiss ich…
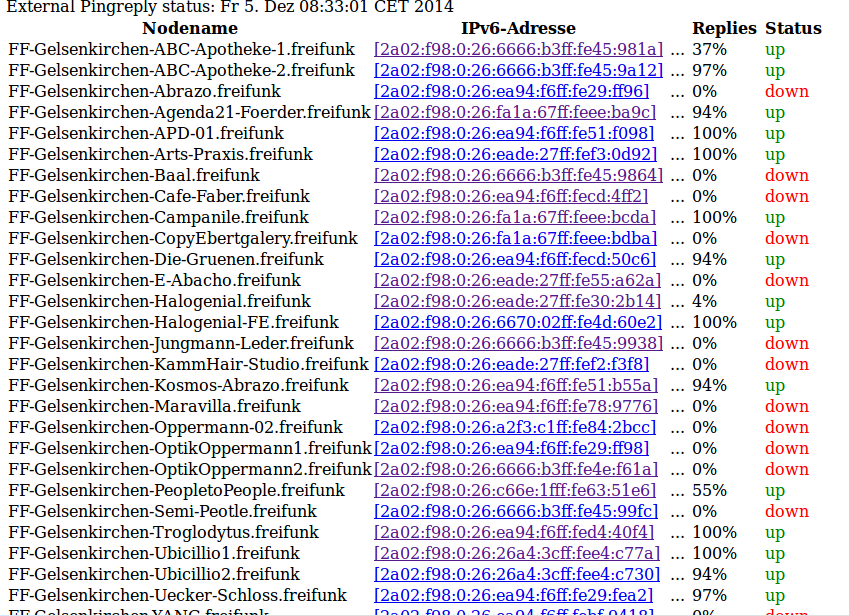
Nach meine Beobachtung fallen Nodes mit einem gewissen Risiko in einen Zustand, in denen sie mindestens selbst keine IPv6-Verbindung mehr von/nach außerhalb des Meshnetzwerkes aufbauen können, d.h. sie kommen nicht übers Gateway, bzw von außen sind sie nicht übers Gateway erreichbar.
Diesen Zustand ist so selten, dass jemandem, der vielleicht nur 3-4 Nodes (oder gar nur einen) bei sich stehen hat kaum auffällt, zumal der Zustand sich nach gefühlt maximal 24h auch von allein wieder gibt.
Die Anzahl der Personen, die mehr als zwei Dutzend Routerchen unter ihren Fittichen haben und diese zudem noch intensiv „hausmeistern“ („wirklich erreichbar oder nur irgendwie auf der Karte“ vs „erreichbar aber auf der Karte verschwunden“), die wird man vermutlich mit Fingern abzählen können.
Daher, nein, kein „Nur Gelsenkirchen-Problem“, meiner Auffassung nach.
Ob es ein Fehler im IP-Stack des Nodes ist oder auf dem Gateway: Keine Ahnung. Es tritt aber unabhängig von der Hardwareplatform (WR740, WR841, ubiquity…) auf. Und unabhängig von der Gluon-Version (2014.3, 2014.3.1, 2014.4.exp)
ohne jetzt konkret etwas tun zu können, bekam ich die folgende Anregung:
<h’neoraider> Auf den Gateways haben wir [… das ist woanders…] die folgenden beiden ip6tables-Regeln drin:
<h’neoraider> -t raw -A PREROUTING -j CT --notrack
<h’neoraider> -t raw -A OUTPUT -j CT --notrack
<h’neoraider> Die sorgen dafür, dass für IPv6 kein Conntrack verwendet wird
<h’neoraider> Das wird nämlich nur für’s NAT von IPv4 benötigt
Man könnte mal bei einigen Knoten minütlich IPv6 Pings absetzten und für den Fall das dieser nicht möglich ist die letzten n Logzeilen in den permanenten Speicher schreiben und neu booten. Nach dem Neustart sollte sich der Knoten dann per Mail o.ä. bemerkbar machen.
Das sind ja nur kleine Datenmengen, der Speicher macht das also sicherlich eine ganze weil mit.
ich habe jetzt einen Node gefunden, auf den ich über fda0::cafe-Adresse immer draufkomme übers Mesh, nicht aber über die 2a02er. Das versagt zu rund 20% der Zeit.
Und wenn ich ein /etc/init.d/network restart &
durchführe, dann klappt es zu 80% wieder…und wenn es vorher ging, geht’s hinterher zu rund 20% nimmer.