der wget-spiderrequest (test alle 5 Minuten) auf ipv4 und ipv6 einer bekannten Webseite mit Timeout 1000ms und 2 maxTries hat immer funktioniert spätestens im zweiten Versuch.
ich hab z.t. auch bei mtr Packetloss auf manchen Strecken bei 50% und mehr… Die Verbindung ist aber absolut stabil (surfen, Downloads, Videostream & co gehen total problemlos) und ein „normaler“ Ping hat nahezu 0% packetloss. Wo das herkommt hab ich nie analysiert aber ich denke darauf will @MPW hinaus
@rotanid, die Jungs die Netzwerk professionell machen, können das sicher besser erklären, aber soweit ich es verstanden habe: MTR ist darauf angewiesen, dass dir die Hosts sagen, wenn die TTL eines Paketes abgelaufen ist. Nicht alle Hosts bzw. Router tun das immer, manche maximal alle x Sekunden.
Es ist schon ein gutes Tool, hat aber seine Tücken bei der Interpretation.
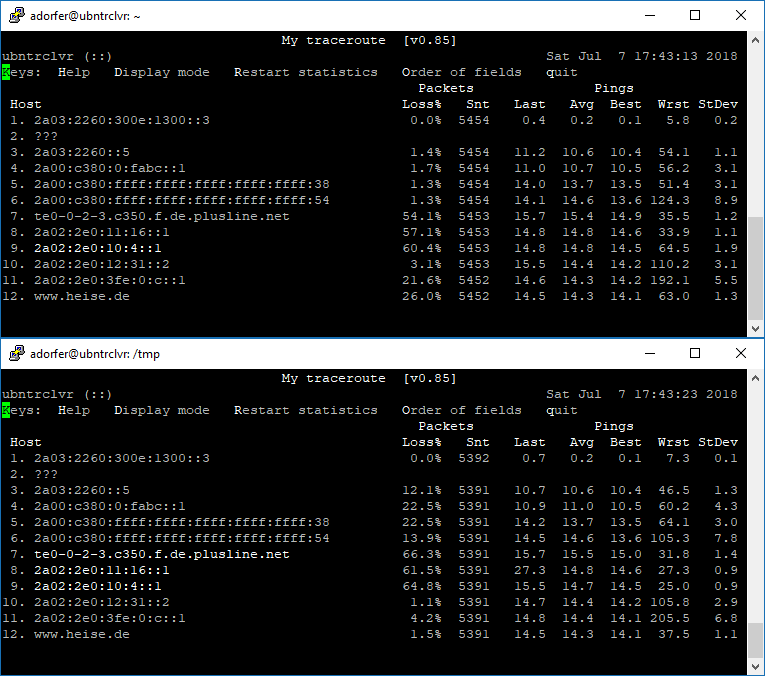
Das gilt für MTR wie für tracer[ou]t[e]. Router sollen routen, Fehlermeldungen senden sie ggf. nur verzögert/nicht für jedes Paket/nur x Pakete pro Zeiteinheit. Tracer senden wiederum für jeden Hop ein neues Paket, welches am Ende des Lebenszyklus mit »Lebensdauer erreicht« vom Router beantwortet werden muß. Während für jedes „ping mail.4830.org“ genau ein (ICMP-) Paket auf die Reise geht, sind es bei einem herkömlichen traceroute wie unten z. B. 21 Pakete: eins mit Lebensdauer 1 (Hop), wird von 192.168.5.33 mit „Lebensdauer überrschritten“ beantwortet. Das nächste mit Lebensdauer 2 Hops, wird von 192.168.177.11 mit „Lebensdauer überrschritten“ beantwortet. Und so weiter, bis bei Paketen mit Lebensdauer 7 sich dann das Zielsystem (mit »alles angekommen hier bei W.X.Y.Z) meldet:
wusel@ysabell:~$ traceroute mail.4830.org
traceroute to mail.4830.org (193.26.120.251), 30 hops max, 60 byte packets
1 192.168.5.33 (192.168.5.33) 3.038 ms 3.004 ms 2.976 ms
2 192.168.177.11 (192.168.177.11) 2.967 ms 3.007 ms 5.913 ms
3 62.155.243.28 (62.155.243.28) 10.673 ms 10.658 ms 10.631 ms
4 217.239.40.10 (217.239.40.10) 17.987 ms 17.969 ms 17.944 ms
5 bgp-ber01.4830.org (193.34.79.248) 20.568 ms 20.553 ms 20.521 ms
6 de2.as206946.net (193.26.120.246) 43.655 ms 40.355 ms 40.325 ms
7 mail.4830.org (193.26.120.251) 42.962 ms 42.962 ms 47.532 ms
Der Unterschied ist, dass bei einem normalen Traceroute eine Rückmeldung über die abgelaufene TTL ausreicht, wohingegen beim MTR das sekündlich erforderlich ist und das machen nicht alle Geräte mit.
Ich hatte mal ähnliche Probleme. es lag an Proxmox. als ich dennserver für die vms aktualisiert habe war das problem erledigt. wenn ihr keine idee habt ggf auch hier mal schauen.
da könnte ich allenfalls downdaten. Da sind wir leider evtl. etwas zu mutig…
Derzeit sind es 4.13.13-5, 4.15.17-3 und 4.15.18-1 auf dem Proxmox im Einsatz und ich sehe keine Unterschiede.
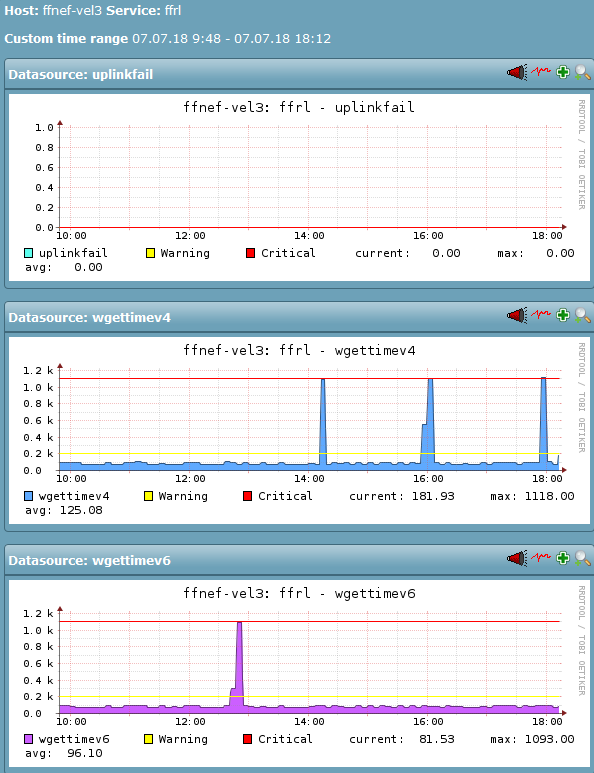
Wobei das Monitoring der äußeren IPs der VMS (als „FO-IPv4“ und der „IP aus dem Prefix des Bleches“) „aus dem Internet“ keine Auffälligkeiten zeigt.
Sprich: Das virtio-ethernet der VM hat keine erkennbare Probleme „zum/ins Internet“.
Mich irritiert gerade, dass du mehrere Kernel gleichzeitig laufen hast. Deshalb nur sicherheitshalber: Bei uns war es das Blech. Also der Proxmox Server, kein Problem in der VM. Ich vermute dass ebtables paket was dabei installiert wurde hat es behoben. kann es aber nicht sagen. Soll nur ein Feedback sien manchmal auch zu schauen ob es auf dem blech ausserhalb der vm hängt…
Ich verstehe Deine Antwort nicht.
Es sind mehrere Systeme betroffen und dort laufen die genannten Kernel.
Wenn Du sagst „nach einem Update ging es“, dann sei doch bitte so konkret zu sagen, mit WELCHEM GENAU es dann besser lief. („nimm den aktuellen Kernel“ klingt für mich nach „Preisliste-aktuell.xls“)
Und ja, ich kenne das Problem, dass die Österreicher je nach verwendeter Prozessorarchitektur durchaus unterschiedliche Kernel als „aktuell“ ausliefern. Daher würde eine fassbare Ansage zu „aktuell“ wirklich doppelt helfen, denn selbst „war der, der vorgestern aktuell war“ würde jetzt nur die Rückfrage von mir bringen: „Für welche CPU?“
Ich hatte vermutet dass du mehrere VM meintest und nicht verstanden hattest, dass ich das Blech meinte. Du hast aber offensichtlich mehrere Proxmox Bleche laufen.
Ich weiss nicht mehr welches Update es war. Ich wollte nur darauf hinweisen, dass ihr ggf. auch oberhalb der VMs auf Fehlersuche gehen sollt, wenn euch die Ideen ausgehen. Hier hat es geholfen. Mehr kann ich gar nicht beitragen.
Im Freifunk-Kontext ich selbst 4 „eigene“, plus 4-5 weitere, um die mich mit kümmere. Und dann noch eine Hand voll außerhalb von Freifunk.
Sprich: Ich kann -wenn es am Hypervisor liegen sollte- durchaus Dinge durchprobieren, zumal da auch eine bunte Mischung von phy/NICs, Prozessoren (Opteron, Xeon, i7) und Boards (Intel, Supermicro, HP).
Ich kenne halt nur noch nichtmal eine sinnvolle Metrik mit der man dieses Problem „gegen einen Datenbannk/Graphen“ laufen lassen könnte. Sprich: Was/wie sollte man sinnvoll messen?
Welche Endpunkte, welche dann herausfallenden Daten.
(Ich habe ansatzweise verstanden, wie das mit den gretunneln funktioniert und dass es eine größere Menge von möglichten Metriken geben könnte. Ich nehme auch gern „mehr“, um dann die passende zu finden.)
hmmm… dein fehler scheint ja ausserhalb eures netzes zu entstehen.
was wusel schreibt könnte relevant sein. sprich dass es kein packetloss ist, sondern lediglich keine rückmeldung der router. evtl könntest du das testen indem du zeitgleich gegen jeden der knoten in der mtr liste einen ping laufen lässt und ob der packetloss hier äquivalent ist. wenn du glück hast lügt lediglich mtr. das würde ich zumindest mal zum ausschluss probieren.
ebenfalls spannend wäre ein externes Ziel (einen eigenen Server) zu tracen und von diesem aus den Rückweg zu prüfen… könnten routing probleme verantwortlich sein? was würde passieren, wenn ein server behauptet er kennt die route aber dort die pakete versacken. würde dann automatisch ein anderer server gewählt, der die pakete in das entsprechende netz routen würde, oder ist damit alles platt?
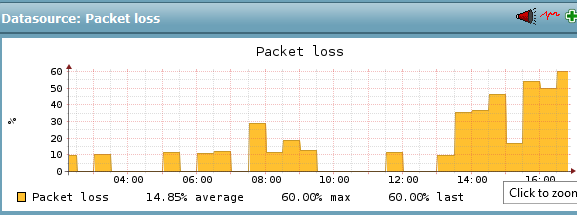
wenn du ping machst, wäre es spannend zu sehen wie der packetloss zustande kommt. burstweise oder gleichmässig
Stehen die Server in einem Verhältnis zueinander? Sind sie gleich konfiguriert? Also könnte der gleiche „Fehler“ in alle Systeme betreffen weil man immer übernommen hat?
Für mich ist schräg, dass da soviel ausserhalb verloren gehen soll… habe aber gerade nur gedanken dazu
Edit: Könntest Du ggf. mal die firewalleinstellungen des proxmox bleches posten? insbesondere die nf_conntrack parameter? ich habe die bei mir hochgesetzt. Hast Du das an dieser Stelle auch? (Ich weiss nicht sicher ob das nötig ist) Weiter: gibt es auf Blechseite Auffälligkeiten im dmesg?
Leider hat sich bislang keine weitere Klarheit ergeben.
Was ich sehen kann:
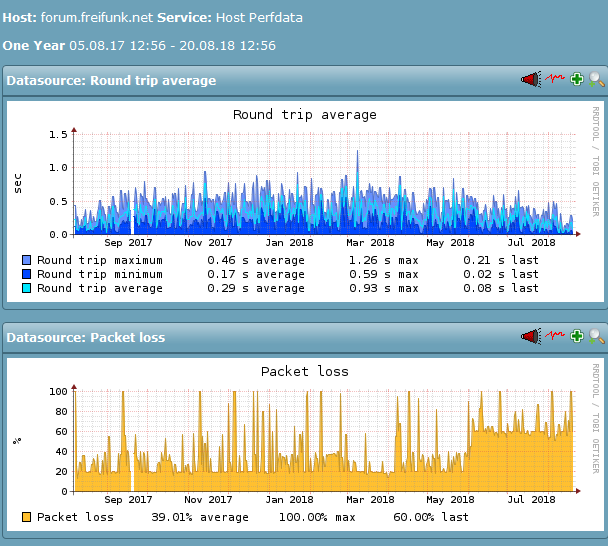
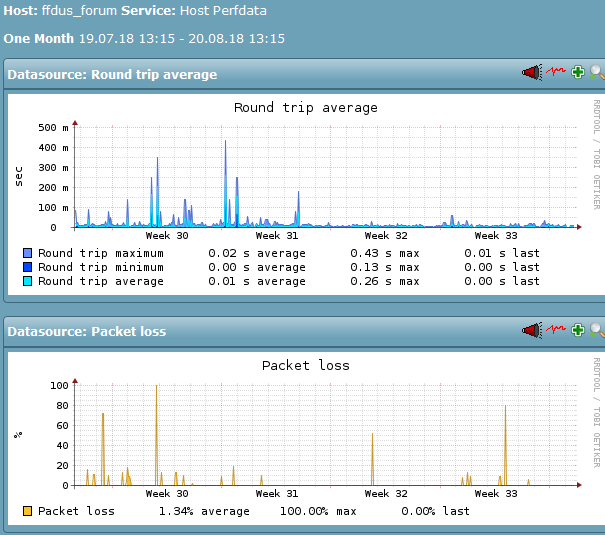
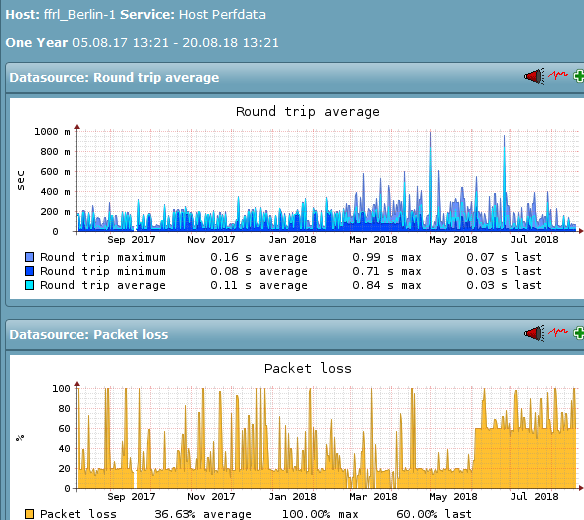
Services, die ich am Berliner-Standort des FFRL vermute, haben seit etwa 4. Juni ca- 13 Uhr irgendeine Änderung. (Achtung: Das Monitoring misst hier nur den Packetloss bei den Probes, bei denen überhaupt ein solcher eingetreten ist, nicht die Fälle in denen 0/5 verloren gehen, daher bewusst überzeichnend.)
eine andere Discourse-Installation (an anderem Standort) ist im gleichen Zeitraum völlig unauffällig, obwohl sie nicht im gleichen Rack (des Monitorings) steht, aber auf einem ähnlichen Setup aufgesetzt ist. Damit sind zumindest effekte "vom Discourse selbst)
Mir ist nicht klar, ob man da Phantome jagd oder nicht.
Prinzipiell bin ich seit einigen Monaten geneigt vorzuschlagen, die (diese!) Forums-VM auf einen Host zu verlagern, der weniger mit Packetloss zu kämpfen hat (egal ob nun IPv4 oder IPv6, da beides irgendwie betroffen ist.). Einfach um die Häufigkeit der „Artikel kann nicht geladen werden“-Fehlermeldungen zu reduzieren.