Leider hat sich bislang keine weitere Klarheit ergeben.
Was ich sehen kann:
- Services, die ich am Berliner-Standort des FFRL vermute, haben seit etwa 4. Juni ca- 13 Uhr irgendeine Änderung. (Achtung: Das Monitoring misst hier nur den Packetloss bei den Probes, bei denen überhaupt ein solcher eingetreten ist, nicht die Fälle in denen 0/5 verloren gehen, daher bewusst überzeichnend.)
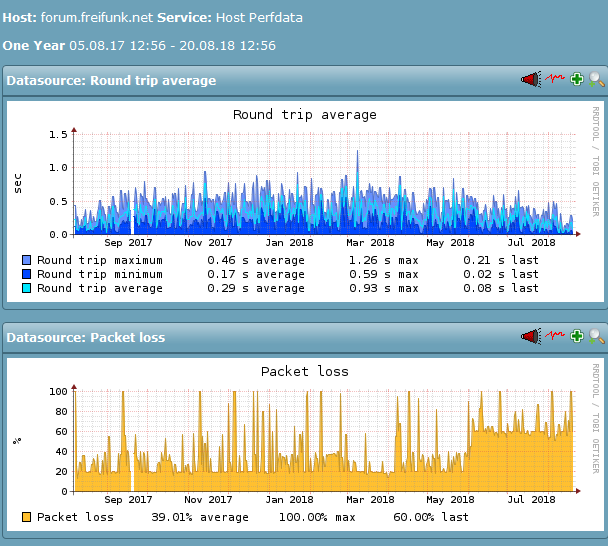
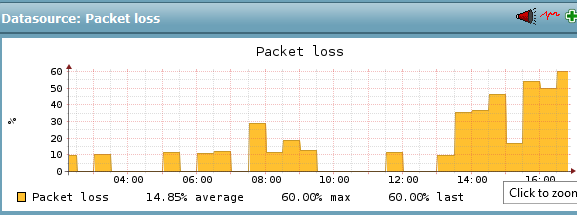
- eine andere Discourse-Installation (an anderem Standort) ist im gleichen Zeitraum völlig unauffällig, obwohl sie nicht im gleichen Rack (des Monitorings) steht, aber auf einem ähnlichen Setup aufgesetzt ist. Damit sind zumindest effekte "vom Discourse selbst)
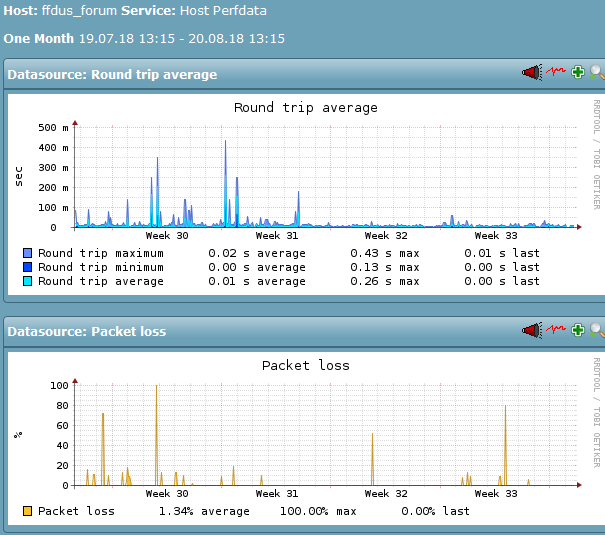
das 1) läuft synchron mit dem Ping-Packetloss auf den äußeren Tunnelenden:
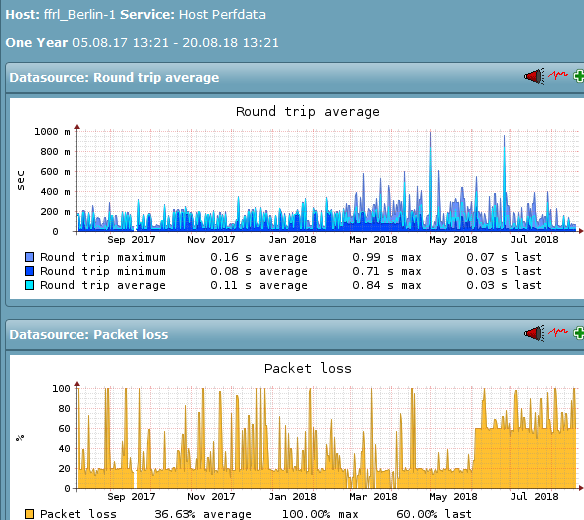
Mir ist nicht klar, ob man da Phantome jagd oder nicht.
Prinzipiell bin ich seit einigen Monaten geneigt vorzuschlagen, die (diese!) Forums-VM auf einen Host zu verlagern, der weniger mit Packetloss zu kämpfen hat (egal ob nun IPv4 oder IPv6, da beides irgendwie betroffen ist.). Einfach um die Häufigkeit der „Artikel kann nicht geladen werden“-Fehlermeldungen zu reduzieren.