ich wollte mal fragen wie es so um die Performance im FFAC steht.
Ich beobachte (Anbindung über Kabel am Offloader) oft verlorene Pings und hohe Latenzzeiten.
Das WAN ist nicht an der vollen Auslastung sonder zu 50% ausgelastete.
Unitymedia Business mit 150DL und 10UL
Es ist auch unabhängig von der Anzahl der Verbundenen Clients am Offloader.
Ist das unter „normal“ zu verbuchen oder doch ein Problem?
In der Tat, die obigen Dinge (des TS) sehen eigentlich gar nicht schlecht aus, Packetloss unter 5% ist doch gut in einem Wlan-Netz.
Die Info, ob der Test aus dem Wlan gemacht wird oder nicht: Ebenfalls wichtig. Vielleicht ist es ja auch Kabel-Link vom Client.
Aber wenn man schon mal dabei ist beim Messen: Vielleicht nochmal ein MTR auf die Nextnode-IP (des FF-Routers) zum Vergleich (ip ist von der verwendeten site.conf abhängig), ebenfalls über mindestens 30 Minuten (des gleichen Zeitraums nach Möglichkeit)
Man kann in komplexen Haus-Installationen sich auch selbst in den Fuß schiessen, z.B. wenn Clients beständig zwischen APs „roamen“ und dabei jeweils erstmal 5-10s Packetloss haben.
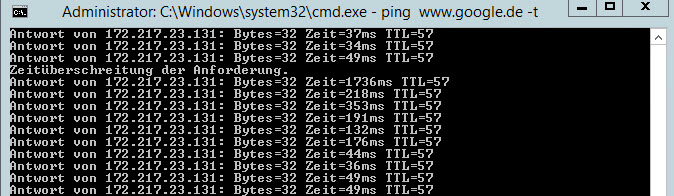
Ich habe WinMTR einmal 20 Min laufen lassen jeweils immer auf www.google.de
Ohne WLAN dazwischen sondern direkt auf der VM und nur mit dem vSwitch am Offloader.
Beim ersten über den FF-Offloader, beim zweiten mal direkt über das WAN.
Ich sehe weder Paketverluste noch hohe Antwortzeiten.
Oder übersehe ich etwas?
Anders gefragt: Was wäre Deine Erwartungshaltung?
Ach so, was den Lag anbetrifft: Vermutlich steht der Supernode irgendwo in einem lokalen Aachener Rechenzentrum und nicht in der Nähe einer der üblichen Monster-RZ-Großstandorte. das sorgt dann halt für 10ms mehr Laufzeit. (Aber ist halt mit 60ms immernoch im Rahmen)
P.S. an einem durchaus belasteten (aber gut nutzbaren) Host, der per ethernet an einem Offload hängt (dann aber eine Wlan-Strecke):
Sprich: Deine Messung da oben zeigt zumindest keine Auffälligkeiten und das Netz sollte gut nutzbar sein.
(Und wenn doch was ist, dann liegt es weder an Packet-Loss, noch an RoundTripDelay)
Kannst du das selbe versuchen mit den 6 Supernodes 01.nodes.freifunk-aachen.de bis 06.nodes.freifunk-aachen.de und schauen ob es da Auffälligkeiten gibt? Die Server sind auf zwei ASe verteilt, bei Problemen sollte eigentlich die eine Hälfte gut funktionieren, die andere nicht. Kann und mag nix versprechen, kann mir aber gut vorstellen, dass die RZ dem allein aus Eigeninteresse auf den Grund gehen wollen, und sich über sachdienliche Tipps von uns freuen
Ich kann das zwar selber nicht reproduzieren (auch Unitymedia, aber ohne Business), habe aber so dtag.net Netze in den Hops gesehen. Kann mir vorstellen dass es da grundsätzlich knirscht, viellei cht wenn der Übergang da an einem anderen Punkt erfolgt der eher ausgelastet ist.
(Und ich sehe grade dass ich die Umleitung zu dtag.net nicht mehr sehen kann wenn ich jetzt paar Stunden später nochmal versuche)
Im Prinzip sind mir nur beim Ping die Paketverluste und die manchmal hohen Latenzen aufgefallen.
Das hat bei VPN dann manchmal schon mal zur Folge dass der VPN-Client sich neu verbindet…
Daher wollte ich eigentlich nur einmal nachhören ob das trotzdem ok ist von den Werten her.
Wann war dieses „Prinzip“: Während der obigen Messungen oder nicht?
(Entschuldige die direkt Rückfrage, aber meine Frage oben war bewusst gewählt.)
Wenn die als Störung empfundenen Effekte während obiger Messungen weiter bestanden, dann kommt man mit dieser Metrik nicht weiter.
Denn die Werte sehen mindestens akzeptabel, wenn icht sogar gut aus.
Aber es könnte halt auch etwas total anderes sein, Daher die Frage.
Sorry, dass ich mich nicht ganz genau ausgedrückt habe.
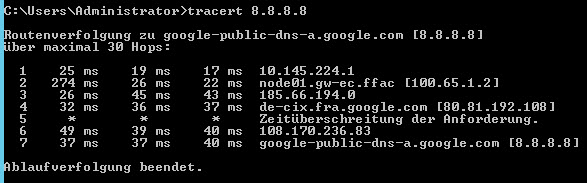
Ich meinte die Traceroute direkt von deinem Anschluss ohne Freifunk-Tunnel zu den einzelnen Supernodes. Durch den Tunnel kann man nämlich bei deinen bisherigen Tracerouten nicht sehen, wo es auf dieser Strecke genau hakt.
Daher wollte ich eigentlich nur einmal nachhören ob das trotzdem ok ist von den Werten her.
Die Latenz ist eigentlich ok, aber auf hohem Niveau beschwert wären 60ms etwas länger als nötig. Wenn möglich wäre daher trotzdem gut das ganze einzugrenzen.
…aber trotzdem mal lustig zu sehen, wie man von »innen« wieder nach »aussen« kommt und dabei einmal komplett am Internet vorbeikommt weil da mittendrin ist nämlich immer noch der FFRL-Backbone (dort wo der Sprung von 1000er auf 3500+ ist )
ich habe nicht alles gelesen. Nur schnell zwei Anmerkungen:
Ich habe es in Batmannetzen schon gesehen, dass man plötzlich komisch große Latenzen hatte und Pakete scheinbar ohne Grund verloren gegangen sind. Das war dann immer auf eine Fehlfunktion im Batman zurück zu führen, entweder auf dem Knoten oder auf dem Gateway. Meist eher letzterem. Ein Neustart kann da schon helfen. Manche Batmanversionen waren dafür anfälliger als andere, 2017.2 z. B. lief bei uns ewig stabil.
Und zu Aachen allgemein: Ich hatte da was gehört, dass ein paar Gateways ausgefallen sind. Ich weiß nicht, ob das noch akut ist und oder deine Probleme damit zu haben könnten. Genaueres weiß ich aber nicht und dazu können die Aachener selbst sicher mehr sagen.
Wo hast du denn so etwas gehört, da ist überhaupt nichts dran!
Es gab mal eine VM die für ein paar Stunden ausgefallen ist, aber das stecken die anderen Supernodes problemlos weg.
Dazu ein Supernode bei dem für rund eine Stunde das Batman Kernel Modul, dank Spectre. Kernel war mit retpoline kompiliert und das Modul noch nicht.
Das wird aber beides nicht mit den beobachteten Problemen zu tun haben.
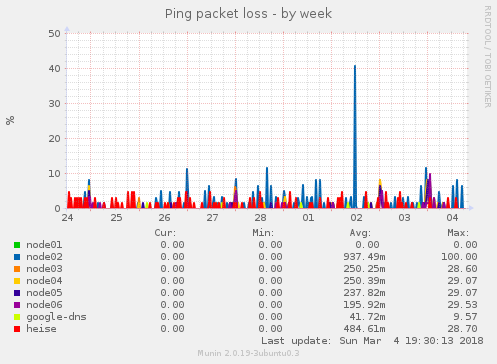
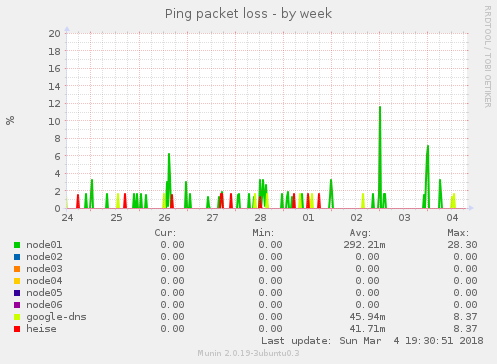
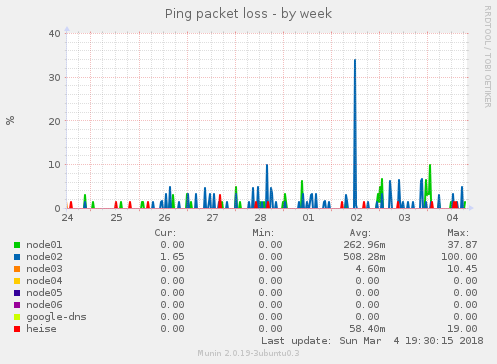
Was ich im Monitoring auch sehe sind immer wieder auftretende Paketverluste zwischen den Supernodes:
Hier scheint mir teilweise schlicht die Netwerkschnittstelle überlastet zu sein. Wir haben Mittlerweile eine Layer 2 Verbindung zwischen allen Supernodes die wir auch schon nutzen. Momentan noch ein wenig improvisiert, das machen wir den kommenden Tagen noch sauber. Dadurch ist dann auf den Netzwerkschnittstellen für die Außenanbindung auch weniger los.
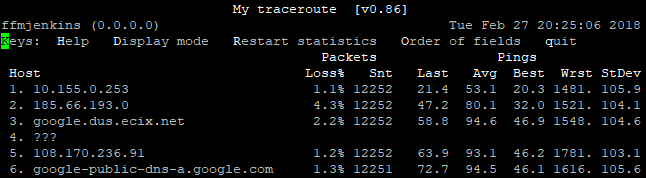
Man sieht ja am Traceroute dass die Durchschnittswerte sowohl zu Relaix als auch Synaix gut sind. Bei Synaix hat man jedoch bei den „Worst-Case“ Werten schon starke Ausreißer, die bei Synaix nicht auftreten.
Anscheinend geht der Weg Unitymedia ↔ NetCologne ↔ Synaix, d.h. Unitymedia legt die Router über NetCologne als Transitprovider.
In den Statistiken kann man zwei Sprünge sehen: Einmal beim Übergang von Unitymedia zu NetCologne und einmal beim Übergang von NetCologne zu Synaix.
Ich würde nun vermuten, dass NetCologne einfach eine stark ausgeleistete Leitung zu beiden Netzen hat, wodurch ab und zu Pakete auf dem Weg längere Zeit in den Caches „hängen bleiben“ oder im schlimmsten Fall gedroppt werden. Mit Unitymedia bzw. Liberty Global kann man nicht so einfach peeren, also kann man das von Seiten Synaix nicht so schnell lösen denke ich.
Soweit ich weiß wollen wir mittelfristig aber eh weiter zu Relaix umziehen (wir haben ja nun auch einen Verein für die Finanzierung gegründet), das Problem sollte sich daher bald lösen.