ich hatte vor einiger Zeit am Rande mal mitbekommen, dass, ich glaube es war @pberndro, gesagt hatte, dass der FFRL einen Antrag zur Änderung der Nutzungsrichtlinien von providerunabhängigen IP-Adressen eingereicht hatte.
Zitat aus den Richtlinien:
7.1 IPv6 Provider Independent (PI) Assignments for LIRs
LIRs can qualify for an IPv6 PI assignment for parts of their own infrastructure that are not used for customer end sites. Where an LIR has an IPv6 allocation, the LIR must demonstrate the unique routing requirements for the PI assignment. Quelle
Status quo ist, dass das immer noch nur für Infrastruktur, nicht für „Kunden“ möglich ist. Ich rechne Freifunknutzer da doch eher zu Kunden als zur Infrastruktur. Einem Router könnte man eine solche Adresse wohl noch geben, aber bis auf einen WLAN-Teilnehmer kann man die Regularieren hier wohl nicht dehnen.
Daher wollte ich einfach mal nachfragen, ob es dazu etwas Neues gibt? Gab es einen solchen Antrag tatsächlich und falls ja, wie ist dieser entschieden worden?
Viele Grüße
Matthias
Hinweis: IP bedeutet hier explizit und ausschließlich IPV6, weil das der Standard ist, muss man es nicht mehr dabei schreiben.
Mein theoretisches Wissen dazu: Ein PI gibt es als min. /44 – alles andere waere zu grosz, als das es jemand entgegen nimmt – und auch /40 soll wohl kein Problem sein.
Hintergrund: /44 ist das groseszte zu routende Netz (Jemand mit einer AS moege mir das bitte bestaetigen). Da ein PI routerbar sein muss, …und man nur an den nibblen brechen soll, ist wohl daher auch das /40 einfacher zu vergeben. Eine Annahme sei auch, dass die Netze so groszzuegig geschnitten sein muessen dass es spaeter keinen Bedarf gibt das Netz zu erweitern, nur weil das Netz zu klein geplant wurde.
Freifunk betreffend: Kurz vor Weihnachten habe ich auch angefangen mir gedanken zu v6 und Freifunk zu machen. Ein paar Stichpunkte dazu:
Wie grosz muesste ein „Freifunk-NG“ denn sein? Jeder Router sollte/muss min. 1 x /56 haben. Wuerde bedeuten das jede Stadt min. ein /40 braucht… hust Wir haben atm in DE ~ 2K Staedte, also alles mit Stadtrecht. Wir sind jetz also bei locker /24 was zB den Foerderverein oder einer anderen Institution uebertragen werden muss.
Aufm Congress habe ich kurz mit mwarning gequatscht. Sind irgendwie mal wieder auf die suboptimale VPN-Situation gekommen. Dass das alles nur Kaesekuchen ist der nichts bringt und sinnlos Probleme macht. Das eigentliche Problem falsch angeht. Gefuehlt waren zumindest wir beide uns einig, dass VPN mehr als Dienst als Notwendigkeit zuverstehen ist. (Ja, ein FF-Router sollte Usern ermoeglichen den Traffic nicht an Ort und Stelle ins Netz fallen zulassen, aber fuers „interne“ Routing nicht notwendig. Darum solls aber nicht gehen.) Ziel war/ist das die Plastekisten sich irgendwie auch im Internet wiederfinden um direkte (vielleicht sogar verschluesselte) Tunnel aufzubauen. In Zeiten von v6 braucht es das private v4 Netz nicht was „ueberladen“ wurde, um Router sowie Teilnehmer erreichbar zumachen. Die Router muessten sich im Internet nur finden, und koennten dann irgendwie geartete vermaschte Cluster bilden. Da bei 128 Bit Addressen anzunehmen ist, dass wir alle nur noch hostnames verwenden brauchen wir auch keine „schoenen“ Adressen. Der langen Rede kurzer Sinn: Wir fanden kein killer-feature fuer ein Freifunk-v6. (Statische Adressen sind ein Streitthema. Habe dazu persoenlich aber noch keine Tendenz.)
Moegliche waere aber auch, innerhalb des Freifunks fc00::/7 zu verwenden. Die wahrscheinlichkeit dass das mal kolliediert soll gering sein, aber wenn dann mal Leute anfangen zB Freifunk an andere Community-Networks anzuschlieszen die auch sehr grosze Bloecke im fc00::/7 verwenden, kann es durchaus zu Problemen kommen.
Persoenlich sehe das atm noch nicht, dass jede Community ein /40 in den Haenden halt und verwalten kann, und glaube nicht so recht dran, dass jede/r wuesste was damit Anzustellen ist. Wie gesagt, um die Ende-zu-Ende-Funktionalitaet im Internet wieder herzustellen, bedarf es keines gemeinsamen Blockes mehr, deswegen haben wir ja jetzt v6. Fuer alles andere gibt es ff07::/7 und sollte uns das nicht reichen bleibt wie gesagt die grosze Reise das jeder ein /40 bekommt. Oder eben der Foerdervein im Bus ein /24 findet und assignen kann.
@MPW: Ich hoffe ich hab den Thread jetzt nicht zu hart geclaimt umd vom Thema RIPE Regularien wegbebracht. Zwecks Kunden und Infrastruktur: Ich habe das immer so verstanden, das ein Kunde kein Kunde mehr ist, wenn er Netze (plural) betreibt, also die Notwendigkeit des Routen hat, bzw. sequmentieren muss. Also jedes Enterprise mit mehr als einem Standort kann und soll ein PI beantragen koennen wenn zB aus administrativer Sicht ein PA nicht sinnvoll ist.
Warum braucht ein Router ein /56?
Ein /64 für die Layer-2 „Client“-Seite und ein /64 für das Mesh => Ein /63 pro „Hood“ (die ja durchaus mehrere Router umfassen kann).
Auf Punkt-zu-Punkt Verbindungen reicht ein /127 (in neueren RFCs sogar als Stand der Technik definiert, bei Babel reichen da sogar die Link-Lokal Adressen => ein /64 reicht dafür deutschlandweit aus, aber sagen wir der Einfachheit halber eines pro Stadt (einfachere Koordinierung)
Damit wäre ein /48 für eine Community (die ja oftmals mehr als eine Stadt umfasst) schon recht großzügig (welche Community hat um 8k Nodes mit Uplink, reine Mesh-Nodes bräuchten ja keine eigenen Netze) und in /32 (was man IIRC als LIR z.B. bekommt) würde locker reichen für ganz .de
Oder was übersehe ich da?
ff07::/7 würde ich aber nicht den Nutzern geben wollen, einfach wegen den möglichen Schmerzen beim Vernetzen. Evtl. für die Infrastruktur, aber ob der Faktor zwei bei den IPs den Aufwand lohnt?
Und was überhaupt ist „ein Router“. (Nein, das ist nicht getrollt. Die Aussage ist einfach unscharf)
Ich kann mich doppelgrau nur anschließen: Warum werden unter V6 Netze tendenziell mit irrwitzig großen Masken designed, immer nach dem Motto „man hat’s ja“.
Betrachtet die Szenarien realistisch und benutzt das.
(Ich geme meinen Single-Service-VMs nur eine /128. Warum sollte ich es größer wählen? Ich sehe kein realistisches Szenario.)
Wir würden schon ein /48er brauchen. Wir haben um die 75 Batmandomänen, pro Domäne derzeit zwei Gateways. Zukünfitg würde ich pro Gateway pro Domäne ein direkt geroutetes /56 planen. Da wäre man dann schnell bei einem 48er.
Meines Wissens sind nach oben keine Grenzen gesetzt. Auch ein /36er müsste routbar sein. Aber das ist halt schon riesig. Der kleinste routbare Bereich ist ein /56. Das ist auch das, was der FFRL mindestens braucht.
Wenn jeder Router sein eigenes Präfix bekommen soll, sollte ein /64er reichen. Aber um Netzdesgin geht es in diesem Thema nicht.
Wir geben jedem Nutzer eine globale IP-Adresse. Das hat mMn nichts mit Infrastruktur zu tun.
Kurz: Bei IPv6 wird nicht geNATet, wenn man dafür keinen guten Grund hat, ist es kaputt. Gute Gründe sind explizit weder „Sicherheit“ (kauf dir ne Firewall) oder „Adressknappheit“.
Bei IPv6 im Allgemeinen ohne Ausnahme nicht angebracht zu sparen oder besser gesagt an künstlich definierter „Knappheit“ die technische Lösung auszurichten. Damit fängt man vielleicht an, wenn das nächste oder übernächste /8 angebrochen werden muss, und davon sind wir noch weit weg.
Beim Antrag geht es allgemein primär darum, dass ein RIPE-Mitglied PI-Space delegieren darf. Das ist einfach ein „Hack“ um Geld zu sparen, denn normalerweise sollte eigentlich dieser „Kunde“ dann einfach RIPE-Mitglied werden.
Das kannst Du gern mal LGI erklären, die per TR69 ihren „Basismodellen“ explizit Prefix-Delegation verbieten. Können täten sie es. Liegt also nicht an „die sind blöde bei Technicolor und Compal“
Ob IPv6 bei LGI nun defekt ist, hängt halt vom Betrachtungswinkel ab.
(Aber auch das derailed diesen Thread)
Ich habe mich vor Freifunk nie damit beschäftigt. Daher kenne ich die Gepflogenheiten, die zu V4-Zeiten herrschten, auch nicht.
Aber muss nicht ein Provider einem Kunden IP-Adressen beider Protokolle anbieten können, die er zu einem anderem Provider mitnehmen kann, sofern er das möchte? Ich kann auch meine Mobilfunknummer zu einem beliebigen Anbieter protieren.
Dafür jetzt 1400 Euro für eine Ripe-Mitgliedschaft hinzulegen, finde ich etwas drüber.
Nochmal zurück zu unserem Kernanliegen: Wir wollen unsere IP-Adressen sowohl über den FFRL als auch über den FFNW routen können.
V4 ist egal, das wird passend genattet. Aber V6 will ich eigentlich nicht natten.
Problem ist: Ein Provider darf einen (End-)Kunden PI besorgen, aber nicht einen anderen Provider (vermutlich um mehr Provider dazu bewegen RIPE Mitglied zu werden).
Wären alle Freifunk-Nutzer Vereinsmitglieder, wäre PI vermutlich kein Problem, die würden dann ja nur „intern“ im Verein genutzt (evtl. wäre ein ganz Großes PI von der Größe ein Problem, aber ein /48 für jede Community sollte dann gut gehen), aber da die (meisten) IPs Dritten zur Verfügung gestellt werden …
Nein, /48 ist die das kleinste IPv6-Netz, welches man praktisch routen (lassen) kann (/24 bei IPv4, JFTR). Und mehr als ein /48 PI zu bekommen ist … nicht trivial. Meine drei /48 wurden nur mit Mühen wie gewünscht als /47 + /48 ausgegeben — wobei man auch ehrlicherweise sagen muß, daß „niemand“ mehr als ein /64 benötigt (4.294.967.296facher Adressraum des gesamten IPv4-Bereichs) und /48 nur aus Gründen des Routings vergeben (bzw. mehr als ein /48 in diesem Falle angefragt (RZ1, RZ2, Home)) werden.
Wieso das? Die Clients können eh’ keine PD und ein /48 bietet 65.535 /64er zur Verteilung neben dem einen für’s Clientnetz. Da Du ein v6-basiertes Mesh hast, kannst Du bequem per BGP intern routen und mußt nicht /56er pro Knoten sinnlos vergeuden.
Als LIR bekommst Du, was Du glaubhaft als Bedarf nennst, Default ist ein /32 (zumindest derzeit):
The minimum allocation size for an IPv6 allocation to an LIR is a /32. Up to a /29 will be allocated upon request with no additional documentation required. You may qualify for an allocation greater than a /29 by submitting documentation that reasonably justifies the request, for example number of existing users and the extent of the organisation’s infrastructure.
FTR: Die BRD hat sich für ihre Verwaltung als LIR registriert und 2a02:1000::/26 bekommen, die Deutsche Telekom 2003::/19. Routen lassen kann man das in /48-Häppchen oder, vorzugsweise, größer. (/56 ist das FFRL-interne Limit.)
Tut das RIPE NCC aus ihrem PI(!)-Space auch (z. B. auf RIPE-Meetings), insofern bleibe ich dabei, daß diese Auslegung bei Neuanträgen ein Fehler des RIPE NCC ist und durch die Vergaberegeln nicht gedeckt. That said, tritt der Änderungsantrag nun in die letzte Phase.
Nein, es geht konkret darum, daß das RIPE NCC DHCP (selbst im LAN oder WLAN) als Delegation (einer Adresse) definiert, was bei v6 gegen die PI-Vergaberegeln wäre. Da bei RA gar keine Adressen vergeben werden, ist das Argument im Freifunk-Bereich schon hinfällig; aber nunja. (Und ja, der Hintergrund für dies Delegationsverbot in den Vergaberichtlinen liegt darin, daß ein ISP gefälligst LIR werden oder eine LIR nutzen soll und nicht für sich als Endkunden(!) zugewiesenen Adressraum für Kunden nutzen.)
Nein. IPs kannst Du entweder als Endnutzer beantragen (IPv4: ERX/LEGACY (vor 1993) bzw. PI (ab 1993 bis 20xx); IPv6: PI) oder von Deinem ISP für die Vertragslaufzeit zuweisen lassen (Dein ISP hat jene entweder als LIR von einer RIR oder einer LIR). Bis 1994 war nicht aller Adressraum korrekt als PA (Provider-Aggregetable) ausgewiesen und/oder in den Verträgen der ISP als zurückzugeben beschrieben, sodaß man damals in der Tat auch 194er IPs noch beim ISP-Wechsel mitnehmen konnte (und als PI labeln).
Aus einigen der Probleme bei v4 (u. a. 700k Routingeinträge) wollte man bei v6 beim zweiten Anlauf lernen, daher ist an sich nur PI-Adressraum frei routbar.
Faktisch ist derzeit, entsprechende Einträge in den Routing-Datenbanken vorausgesetzt, jegliches v6-Netz ab /48 frei routbar (also auch aus großen LIR-Blöcken), mit ca. 70k an Routen ist das v6-Internet auch noch überschaubar.
Wir nutzen daher für’s Clientnetz /64er aus unseren /44 vom Förderverein, für Infrastruktur z. Zt. Netze aus einem /44 einer LIR (‚gemietet‘ gegen jährlichen Einwurf kleiner Münzen).
Sehr geil, endlich jemand, der auf meine Frage antwortet. Danke
Was bedeutet „PDP“, steht das für „policy development policy“? Würde zumindest inhaltlich Sinn ergeben.
Also da nur Leute gesagt haben, dass sie eine bessere Lösung wollen, wird das jetzt erstmal beschlossen? Wie lange dauert das dann erfahrungsgemäß noch? Der Beitrag ist erst von gestern.
Seid ihr denn Vollmitglied für 1400 €/a oder ist da Ironie drin? Dass das V6-Netz an sich nicht viel kostet, ist klar.
If the WG chair determines that the WG has reached consensus at the end of the Review Phase, the WG chair moves the proposal to a „Last Call for Comments“ and the Concluding Phase starts. The Last Call period lasts four weeks.
[…]
At the end of the Last Call period, the WG chair will evaluate the feedback received during this period and decide whether consensus has been achieved. If there is no feedback from the community at this stage, this is likely to be regarded as consensus and it will mean the previous call of rough consensus from the WG chair at the end of the Review Phase still holds.
Wir sind ja (noch) nicht mal eine jur. Person (Das ist auch primär der Grund, warum noch kein PI für FF beantragt wurde; AS war notwendig, PIv6 kann warten.)
Da LIR zu werden derzeit der günstigere Weg ist, noch an v4-Adressraum zu gelangen, wäre LIR latent interessant; da wir routbaren v4-Adressraum zur Verfügung haben, fehlt aber der konkrete Bedarf. (IPv4 PI gibt’s seit vielen Jahren nicht mehr, und kaufen oder mieten von IPv4-Space ist recht teuer, z. B. CHF 80,--/Monat für ein /24 wie das vom FFNW verwendete.) Im Zweifel wird v4 bei uns halt per Reverseproxy bedient (so z. B. unser Forum, welches z. Zt. auf unserem Blech in Berlin läuft) — v4 ist letztlich Legacy, das muß auf Dienstebene nicht mehr schön sein.
Bei v6 ist PI (da noch verfügbar) deutlich interessanter, anstatt LIR zu werden; und die EUR 50,--/Jahr (zzgl. LIR-Spesen, also i. d. R. mindestens Mehrwertsteuer; typisch unter EUR 100,--/Jahr) sind auch einfacher zu refinanzieren als die gut EUR 100,--/Monat für die RIPE-Mitgliedschaft (abzgl. Rückvergütungen; zzgl. einmalige Aufnahmegebühr). Und die Adressen als LIR behält die LIR nur solange, solage sie als LIR beim RIPE NCC mitmacht und mitzahlt: Gibt die LIR ihr Geschäft auf (oder wird mangels Zahlung geschlossen), verfällt die Allokation und prinzipiell auch alle Suballokationen (keine Ahnung, wie das in der Praxis gehandhabt wird).
Lange Rede, kurzer Sinn, deshalb ist PI aus meiner Sicht interessant: man bleibt unabhängig, muß wohl niemals renumbern. Und ein /48 umfaßt nun mal satte 65.500 /64er Netze — das sollte ein, zwei Monde reichen Selbst in /56er aufgeteilt blieben 256; wieviele „Domänen“ habt Ihr aktuell?
Du denkst imho zu sehr in FFRL-Tunneln. Obige Aussage läuft auf 150 /56 gen FFRL hinaus, aber welche Adressen gibst Du denn den Batman-Meshes? Zwei /64, jeweils das erste aus dem /56 des jeweiligen GWs? Was nützt Dir das zweite?
Nur kurz: Mein Router hier hat z. B. folgende Routen, einmal über 1&1-VDSL (VLAN 6), einmal über Unitymedia (VLAN 3):
default via fe80::cece:1eff:fe00:0000 dev eth0.3 proto ra metric 1024 expires 1654sec hoplimit 255
default via fe80::3a10:d5ff:fe00:0000 dev eth0.6 proto ra metric 1024 expires 1731sec hoplimit 255
Preisfrage: über welches Interface geht es zu heise.de?
root@gw-gt:~# traceroute -6 2a02:2e0:3fe:1001:7777:772e:2:85 | egrep "^ 2|\!X"
2 de-gut01a-cr01-ca1.gut.unity-media.net (2a02:908:d500:1::1) 24.756 ms 24.743 ms 24.702 ms
11 2a02:2e0:3fe:0:c::1 (2a02:2e0:3fe:0:c::1) 20.071 ms !X 26.615 ms !X 25.208 ms !X
Augenscheinlich dem ersten in der Liste. Und solange die UM-6490 läuft, bleibt das auch so, selbst wenn zwischen UM und Plusline kein Byte mehr fliessen könnte.
Ich kenne nicht den Hintergrund der /56 pro Gateway pro Domäne, aber ich denke, daß man das mit BGP & OSPF anders sinnvoller (funktionaler und mit weniger Adressen) hinbekommt. Aber das führt meilenweit von der Ausgangsfrage weg
Ein 64er kann ich nicht separat routen lassen. Die Pakete müssten dann vom ersten Gateway, was das /56 entgegen nimmt, zum zweiten (oder dritten) gekarrt werden. Mit separaten /56ern kann ich per Routenexport die Pakete direkt ans richtige Gateway schicken.
Genau davon wollen wir ja weg. Aber das geht nicht, solange IP[V6] nur über das AS von denen laufen kann.
Also wenn ich dich richtig verstanden habe, könnte man für etwa 100 €/a LIR werden, providerunabhängige Adressen erwerben und diese (sofern die beiden mitmachen) über den FFRL und den FFNW routen lassen. Theoretisch sogar auch direkt über den Hoster, wo das Gateway steht, falls die das mitmachen.
Und die könnte man auf der eigenen Infrastruktur auch nach derzeitigen Ripe-Bedingungen an WLAN-Clients ausgeben, weil es unsere Adressen sind und wir sie nicht noch an eine andere juristische Person weitergeben.
Intern (in der Community oder wenn man sich darauf einigt auch in den Freifunk-Backbones) kann man auch einzelne /64 routen, völlig problemlos.
Richtung Internet ist die kleinste Einheit das /48, also muss man intern schauen, wie alle Adressen in den /48 untereinander sich erreichen können… (Damit braucht man wieder Tunnel und/oder „Richtfunk-Backbones“).
Sehe also keinen Vorteil von den /56, außer das man damit 99% Platz verschwendet…
Aber dann ist das /56 ja der Wunsch, dass die einzelnen Communities die Routen vorher aggregieren, jedem Router ein /56 zu geben ändert an dem Problem der zuvielen Routen ja nichts.
Ob es 10.000 /64 oder 10.000 /56 sind, ist für die Router das gleiche, aber die 10.000 /64 passen theoretisch in 40 /56 … (In der Praxis natürlich deutlich mehr, weil man seltenst das /56 ganz voll bekommt.)
Natürlich kannst Du ein /64 separat routen; die Frage ist, ab wo.
root@de6:~# traceroute -6 2001:bf7:170::5
traceroute to 2001:bf7:170::5 (2001:bf7:170::5), 30 hops max, 80 byte packets
1 gateway (2a02:e00:ffec::1) 6.394 ms 6.409 ms 6.785 ms
2 strato.dus.ecix.net (2001:7f8:8::1a44:0:1) 11.085 ms 11.088 ms 11.073 ms
3 xe-0-0-1.core-b30.as6724.net (2a01:238:0:30ad::1) 22.760 ms 22.594 ms 22.721 ms
4 2a06:e881:1706:1::1 (2a06:e881:1706:1::1) 18.199 ms 18.175 ms 18.179 ms
5 mueritz-bgp1.mueritz.freifunk.net (2001:bf7:170::5) 31.206 ms 31.203 ms 31.190 ms
Das ist ein /64, welches innerhalb unseres AS geroutet wird (Internet => Community-IX Berlin => Falkenstein).
root@blackstar:~# birdc6 show route | grep 2001:bf7:170
2001:bf7:170::/44 via fe80::1a0a:1 on Tgw05 [i_Tmuer05 2017-12-06] * (100) [i]
2001:bf7:170::/64 via fe80::1a0a:1 on Tgw05 [i_Tmuer05 2017-12-06] * (100) [i]
Nach außen wird natürlich nur das /44 announced:
root@blackstar:~# birdc6 show route export e_cix_rs1 | grep 2001:bf7:170
2001:bf7:170::/44 via fe80::1a0a:1 on Tgw05 [i_Tmuer05 2017-12-06] * (100) [AS206813i]
root@blackstar:~# birdc6 show route export e_dir_lwlcom | grep 2001:bf7:170
2001:bf7:170::/44 via fe80::1a0a:1 on Tgw05 [i_Tmuer05 2017-12-06] * (100) [AS206813i]
Aber wo das /64 intern hängt, entscheidest Du.
Jein. Ich gehe von einem /64 per Mesh aus. Und dann gibt es tendenziell auch nur ein (aktives) Gateway, über das v6-Antworten ins Mesh kommen — raus gehen können sie im Grunde über andere Wege, aber das macht jegliches Debugging … unspaßig.
Zu Deinem Ansatz mit zwei /64(?) je Mesh, notwendig bei zwei /56 bei zwei GWs, hatte ich ja schon was geschrieben.
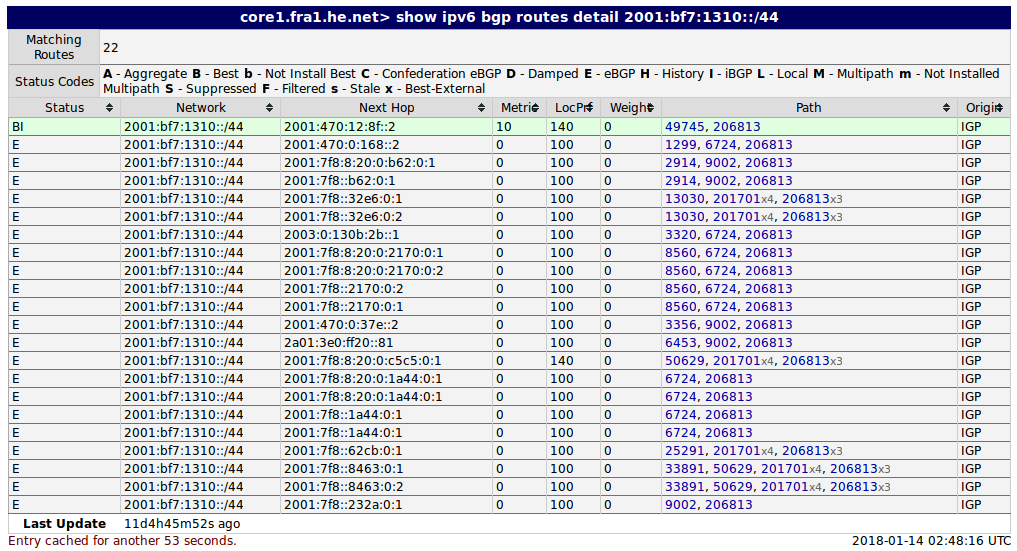
AS201701 (FFRL) routet auch unsere Netze (AS206813); zumindest teilweise und hier insbesondere 2001:bf7:1310:/44 — unsere Freifunk-Client-Netze:
Nope, gut 100 € pro Monat (1400 EUR/Jahr, abzgl. Überschußkompensation; zzgl. Aufnahmegebühr).
PI, provider independent, Adressbereiche kannst Du für grobe Richtung 100 EUR/Jahr von jeder LIR auf Dich als Privatperson, Firma, Verein, … Dir zuweisen lassen. IPv6 only (IPv4 ist alle), und falls RIPE NCC auch nur den Hauch einer Idee gewinnt, Du könntest (böse, böse!!!) an Dritte Adressen ›delegieren‹, werden sie den Antrag ablehnen. Hint: Gebühr zählt für »Adressblock eingerichtet«, somit zahle ich für mein /47 + /48 jährlich zusammen 50 EUR (plus ISP-Offset), da zusammen bestellt und (nach Diskussion) zusammen zugeteilt. (Nein, die Regularien machen aus meiner Sicht keinen Sinn. Aber da ja auch die RIPE-Gebühr nicht mehr nach Adressraum sondern per LIR berechnet wird …)
Ja, wobei die dann den Bereich in deren AS übernehmen müßten, oder intern Peering/Upstream machen. Hetzner & OVH machen derlei dem Vernehmen nach nicht.
Was Du mit Deinen Adressen tust, ist ein ganz anderes Pferd. Derzeit würdest Du als »Freifunk XYZ« wahrscheinlich kein IPv6 PI bekommen, weil das RIPE NCC Dir unterstellt, daß Du per [W]LAN Dritten IPs aus dem PI-Bereich ›delegieren‹ (per DHCP/RA) würdest.
Daher habe ich für mein Zuhause-PIv6 explizit für’s WLAN PA vorgesehen. (Was ich durch ISP-PA oder eines meiner PA-Netze (von /48 bis /40 hätte ich da was) erschlagen kann.)
Und weil das alles eher lächerlich ist, möchte ich, daß das RIPE NCC seine fragwürdige und singuläre Auslegung, DCHP oder gar RA statuierten eine ›Delegation‹ von Adressen, aufgibt, statt einen schon komplizierten Policy-Text mit weiteren Ungereimtheiten noch komplizierter zu machen.
Faktisch hat das RIPE NCC ja genau kein Problem damit, z. B. auf RIPE-Meetings regelmäßig Dritten IPv6-Adressen aus ihrem PIv6 zu ›delegieren‹, dann kann es nicht sein, daß die identische Organisation dies anderen verwehrt.
Yo, klar.
root@us1:~# birdc6 show route | wc -l
113074
root@us1:~# birdc show route | wc -l
667137
Bei IPv6 sprechen wir aktuell im globalen Routing über gut 110.000 Routen (ich bin überrascht; das wächst augenscheinlich grade fast exponential) — bei v4 über knapp 670.000. Und bei »ein paar Hundert« Communities würde der Wechsel von /56 zu /64 FFRL-intern eine Kernschmelte auslösen?
[Gut, ich bin eine Serverschabe, ich route in Software. Es soll noch ein paar Leute da draußen geben mit ›echten Routern‹ und ›echten Problemen‹, i. e. Speicherüberlauf durch die Routenanzahl. Mehr als ein »ist wohl ein Hardwareupgrade fällig« vermag ich aber nicht zu entgegnen.]
[Gut, ich bin eine Serverschabe, ich route in Software. Es soll noch ein paar Leute da draußen geben mit ›echten Routern‹ und ›echten Problemen‹, i. e. Speicherüberlauf durch die Routenanzahl. Mehr als ein »ist wohl ein Hardwareupgrade fällig« vermag ich aber nicht zu entgegnen.]
Ich deraile mal: Ich versteh dich nicht ganz… Ueber was fuer eine Anbindung reden wir, dass man mit Linux und des overhaeds bei groszen lookups, Probleme hat seine Links zu saturieren? Bei besagten 670K+110+K Routen.
Die Kisten mit Cumulus Hardware-Support, werden bezahlbarer, bzw. gibt es auch schon gebraucht. Wegen den Lizenzen: Fuer Freifunk/Einen guten Zwegen/FOS-Commuitys gibts sicherlich Sponsoring. (So ne Gruppe in NL bei der man Netzwerk-Gear fuer FOS-Events leihen kann, hat u.a. von Google mal 10 oder 20 „alte“ Teile bekommen. Die Hardware verspricht oft non-blocking, weils wie „frueher“ dann am Ende doch in Hardware gemacht wird. Nur die „Programmierung“ laeuft halt wie gewohnt mit iproute2, und neuerdings mit ifconfig2, was seit ein paar Monaten quell-offen ist. Und BPF macht ja auch immer mehr Fortschritte. TL;DR; wer jetz noch unbedingt mit klassischen vendor-OSes versucht SDN zu machen, leidet unnoetig.)
Wegen v6: Das ein /56 fuer einen Router sogar verpflichtend ist, hatte ich nicht auf dem Schrim. Ich bin immer davon ausgegangen dass sei eine Empfehlung/Notwendigkeit, um auf einem Router so oder so erstmal 256 lokale Netze bereit zustellen oder zu koennen. Also auf zB 256 Interfaces; physisch oder virtuell sei dahingestellt. Oder eben verschiedene Netze fuer verschiedene Dienste. Labarababer. Halt getrennt Netze. Koennen ja auch VLANs oder VxLANs sei. Und wenn die 256 Netze nicht reichen, dann bekommt dieser Router halt ein groeszeres Netz. Also /48. Und das ein einzelner Router ein komplettes /48 bedient, da muss jemand maechtig kreativ werden. Da ist dann also genuegend Luft. Fuer alles was „nur“ auf dem wire passiert, koennen die Geraete eh ueber fe80 mit einander reden. Ich kann also mein Routing, und mein Assignment problemlos mit Hilfe von link-local machen, weil ankuendigen tut der Router ja nur sein /56, und wo und wie im Zweifel eine Host-Route (/128) auf diesem Router behandelt wird, ist die Sache des Routers und wieviel Power der hat bzw. was mein Bedarf ist.
Und selbst mein Telekom-Plaste Router bekommt ein /56 vom Customer-ISP. Heiszt das ich zuhause fuer meinen IoT-Shit und Home-Entertain 256 lokale Netze betreiben kann. Gaeste WiFi, such dir was aus. Das selbe sollte daher auch bei einem Plaste-In-The-Wild-Freifunk-Router gelten. Nicht sinnlos knaussrig sein. Wenn 2000::/3 voll ist, gehts halt mit 4000::/3 weiter, oder nicht? Wenn dann absehbar ist das 128-bit doch nicht gereicht haben, muessen wohl 1024 oder 4096-bit her. Ich sehe da jetzt nicht zwangslaeufig ein Problem. Wie gesagt, ein einzelner kleiner Endgeraete-Router muss erstmal das /56 voll machen, also 256 Netze bedienen muessen. Ob das je passiert ist nicht genau abzusehen, aber lieber zu groszzuegig als in 10 Jahren dann schon wieder feststellen, dass man ne doofe Entscheidung getroffen hat. Und aeusserst spezielle Host-Routen kann man in seinem eigenen Netz (> /56) ja eh nochmal gesondert behandeln. Fuer alles andere gibt es native v6-features, und DNS („dynamisches“ DNS und Service-Records z.B.)
Wegen einzelner /127 fuer peer-to-peer-links in einem Infrastruktur-/64: Das macht wohl alles nur kaputt und schwierig, laut hoeren sagen. Wenn zwei Interfaces miteinander reden, dann soll das einfach wie in jedem anderem Netz in einem /64 passieren. Man will so Sonderlocken erst gar nicht wieder en vogue werden lassen. Ausserdem erschwert es nur sinnfrei den administrativen Aufwand. Benachbarte Router (physisch, wie virtuell) koennen auch einfach so, immmer, in fe80:0/64 miteinander reden. Denn ich „weisz“ ja auf welchen Interfaces ich ueberhaupt routen und peeren moechte, und den rest macht das neighor-discovery. Da muessen nichtmal extra Bloecke ausgedacht werden. Einige Routing-Dienste haben daher ja nun auch support fuer Authentifizierungsmethoden, um „sicher“ zugehen, mit wem man da eigentlich grad redet und sich austauscht.
Auf die anderen Aussagen mag ich grad (noch) nicht eingehen, obwohl da einige spannende/interessante Punkte dabei waren.