wenn ich FF Aachen nutze erhalte ich stark schwankende Round trip times, was direkt an meinem Internetanschluß nicht der Fall ist.
Hintergrund: Es beschweren sich Benutzer, dass Videocalls abreißen.
Wäre toll, wenn jemand einen Lösungsansatz hätte.
folgende Aufbauten - in einem Netz (WAN vDsL mit 100/50 Mbit/s) für mich ganz allein
Diese Aufbauten habe ich auch an einem Unitimediaanschluss ohne große Unterschiede nachvollziehen können.
FB 7390
hinter FB ein Offloader
hinter Offloader nur ein LAN-gebundener Client
auf diesem Client ping auf 8.8.8.8
Zeiten zwischen 37.328 ms und 949.006 ms mit diversen Timeouts
Pings meist um die 55.xxx bis 70.xxx ms aber alle 60 Sekunden Einbrüche auf Extremwerte oder Timeouts
FB 7390
hinter FB ein ArcherC7
hinter Offloader nur ein LAN-gebundener Client
auf diesem Client ping auf 8.8.8.8
Zeiten zwischen 39.104 ms und 936.955 ms mit diversen Timeouts
Pings meist um die 55.xxx bis 70.xxx ms aber alle 60 Sekunden Einbrüche auf Extremwerte oder Timeouts
FB 7390
hinter FB nur ein LAN-gebundener Client
auf diesem Client ping auf 8.8.8.8
Zeiten zwischen 18.422 ms und 24.660 ms
Bitte versuche doch mal einen „mtr“ oder anderweitiges Tool auf die 8.8.8.8 stehen u lassen und nach den Werten zu schauen.
(Ich könnte jetzt blind auf mindestens ein Dutzend verschiedene mögliche Fehlerquellen deuten.
Gibt es irgendwelche regelmäßigen „komischen“ meldungen im „logread“ des Freifunk-Routers an dem der Client hängt?)
In welcher Subdomain ist der Router denn?
Ich hab den Thread mal nach „aachen“ verschoben, damit die Leute dort auch merken, dass sie die Frage betrifft.
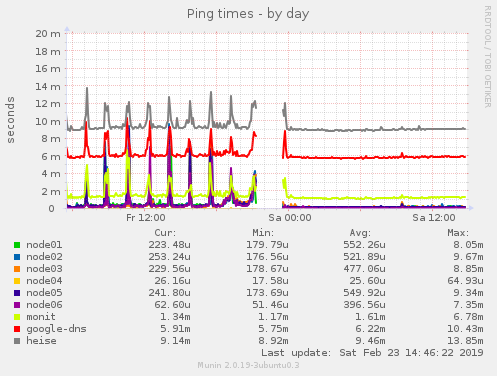
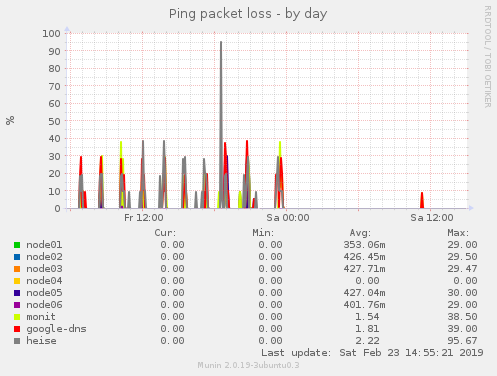
Wir hatten ziemliche hässliche latenz Spitzen die auch zu packetloss geführt haben. Letztlich konnte ich es auf das Kartenbackend von Hopglass zurückführen. Nachdem wir dies abgeschaltet haben schaut es beudeutend besser aus:
@PetaByteBoy hat am 21.01.19(?) am Hopglas etwas commited was wir schon etwas länger getestet hatten: Entzerrung der Requests der 3 Datentypen, d.h. zumindest „Effekt 30% weniger, mindestens“.
Aber auch wenn man die glättet wäre es weiterhin ziemlich viel, die Phasen zwischen den Peaks sind der kombinierte Traffic aller Nutzer und incl Verwaltung sowie yanic Karten backend.
Es gibt sonst noch einen Unterschied zwischen alten Versionen vom hopglass-server und yanic: Wir haben mal die Broadcast-Anfragen an alle Netzwerkteilnehmer geschickt (ff02::1) statt an die multicast-Adresse für alle respondd-Geräte (ff02::2:1001). Das ist in der Standardconfig des aktuellen master auch geändert worden.