Naja, automatisch restarten lassen kannste prozesse ueber inittab oder systems (je nach linux distribution) dafuer brauchste eigentlich keine scripte.
Anders sieht es mit dnsmasq aus. Hier habe ich deshaufigeren beobachtet das er keine ips mehre verteilt. Hier habe ich ein scriot geschrieben was die modify time des leasefiles uebereacht und ggf den dnsmasq restartet.
Ja, das sehe ich hier bei uns im Netz recht häufig.
Seitdem ich automatisiert die DNSMasq prozesse restarten lasse kamen keine User beschwerden mehr
Das schlimme ist das der DNSMasq sich nicht beendet und gelegentlich auch nach 1,5h wieder berappelt.
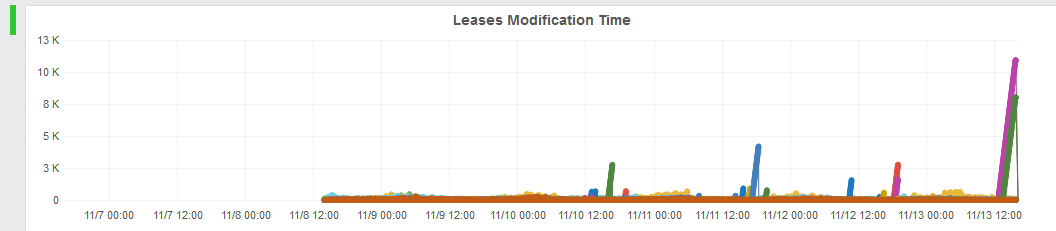
Aktuell sieht es z.B. bei uns so aus (mit meinem Skript)
Seltsames Problem, das habe ich so noch nicht beobachten können.
Wir überwachen bei uns die DHCP Leases via collectd und bis jetzt habe ich diesen Fehler mit DNSMasq noch nicht beobachten können. Welche Distro nutzt ihr denn?
Unsere ist umfangreicher und hat auch noch Stateless DHCPv6 mit drin, aber ich hatte genau die gleiche Version wie fragstone, allerdings auch nie solche Probleme
Ps: ihr habt aber echt krasse Max Werte beim Cache und den leases o.O
Wie sieht denn eure Config aus? Evtl ist es ein Setting was wir beide in der Config haben aber bei @fragstone fehlt.
DHCPv6 brauchen wir bei uns nicht da die meisten Geräte dies eh nicht ordentlich unterstützen oder es explizit aktiviert werden muss. Android z.b. kann es per Design nicht.
Was die DHCPv4 Leases angeht: 1h ist schon ganz ok, weniger macht nicht viel Sinn da dann die Clients die länger im Netz unterwegs sind sonst zu häufig nachfragen. Konfiguriert sind maximal 2250~ Leases Pro Supernode. Das Mesh bei uns hat maximal 8K Adressen. Wir nutzen keine /16 sondern /19 für das Mesh, mehr macht keinen Sinn da das Mesh niemals so groß skalieren kann.
Warum der Cache so groß ist weiß ich nicht, ich glaub wir wollten viel im Ram vorhalten. Davon haben wir auf den Supernodes mehr als genug.
dnsmasq startet man sinnvoller weise gar nicht erst. Denn der kommt allem Anschein nach in Netzsegmenten mit >200 clients nicht mehr stabil daher, egal wie performant der Host ist. Da scheint schlicht irgendein (dead-)locking zu passieren.
Meiner Meinung nach sollte das Überwachen von Diensten (und deren automatischer Restart) nur dann erfolgen, wenn es sich um einen Dienst handelt, der per default "eigentlich"™ funktioniert.
Einen Dienst mit solchen Hack-Scripts am Laufen zu halten, weil sich der Dienst von selbst alle paar Stunden weghängt: Da würde ich nicht ohne große Not am System herumdoktern, sondern das Problem an der Quelle bekämpfen. Also eben kein „Restart-Script“:
Ach ja, wenn es wirklich nicht anders geht und man eine logfile-bedingung erkannt hat, die sofortiges Handeln möglich macht (und wo das auch sinnvoll ist): swatch