ich vernetze gelegentlich bei mir in der Region Accesspoints mit Ubiquiti Richtfunk auf Stockfirmware. Bis ca. 800m nutze ich die Nanostation 5AC Loco, für die Strecken bis 5km nutze ich die Powerbeam 5AC. Die Antennen hängen jeweils an einem eigenen PoE, direkt danach kommt stets ein ERX mit unserem Community Image (Gluon 2020.2.2).
Bei den Nahbereichsinstallationen funktioniert dieses Konzept richtig gut. Auf der Map werden die Connections stets mit 100% Übertragungsqualität angezeigt. Und es läuft einfach gut.
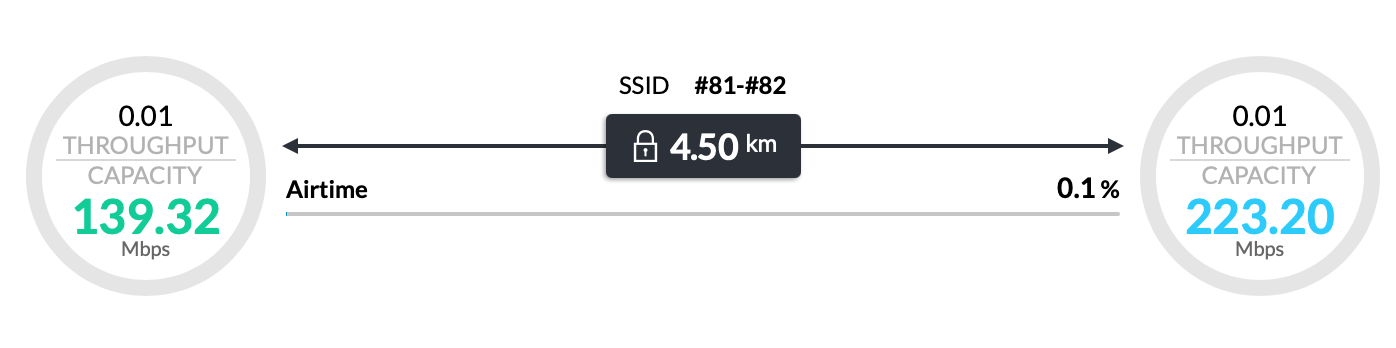
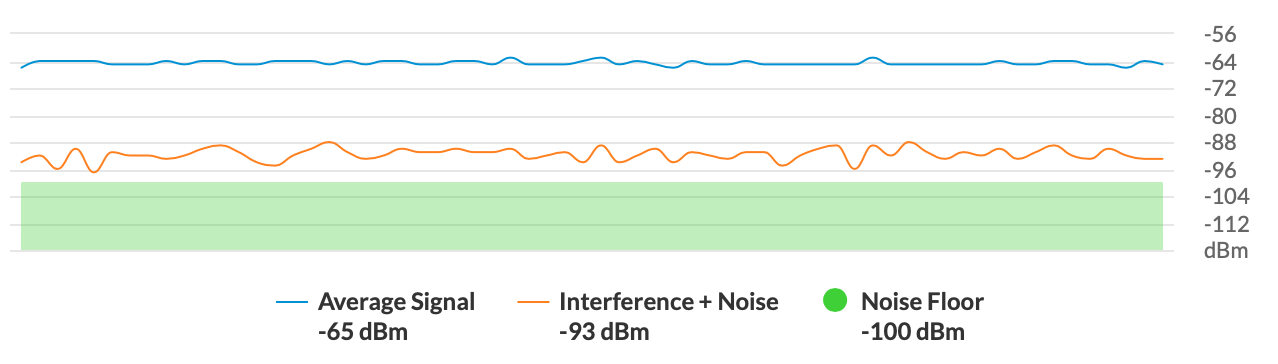
Bei den Weitstrecken (4-5km) sieht es hingegen anders aus. Dort meldet unsere Community Map, dass die Verbindungsqualität zwischen 0% und 100% schwankt. Betroffen sind zwei unterschiedliche Linkstrecken. Im Stock-Backend direkt auf den betroffenen Antennen sieht man nichts von Problemen. Die Signalstärke liegt bei -65dB, sowohl mit 40MHz als auch 80MHz liefern die Verbindungen ordentliche Bandbreiten. DFS Signale sind ebenfalls kein Problem.
Wenn ich auf der Richtfunkstrecke einen Ping von einem Ende zum anderen laufen lasse, läuft der einwandfrei durch. Kein Verlust bei 1000 Paketen.
Hat jemand eine Idee, was der Grund seien könnte, dass Gluon hier so schlechte Übertragungsqualitäten misst?
Magst Du nochmal das Fehlerszenario beschreiben.
Wer meldet genau was in dem Zustand „Fehler“?
(Ich wüsste jetzt ein Szenario, was evtl. zu Deiner Beschreibung passt, aber evtl. habe ich es auch falsch verstanden. Daher spare ich mir mal die Ausführungen dazu, weil das dann überhaupt nicht hilfreich wäre.)
Der „Fehler“ ist die Beurteilung der Linkqualität durch Gluon.
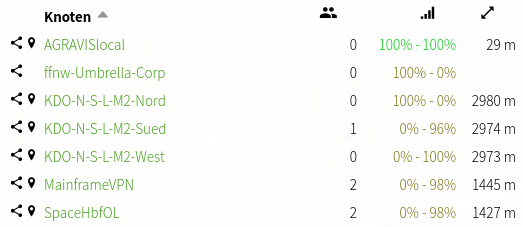
Die beiden Locos (Grundschule, Jugendclub) kommen auf 100%-100% in der Qualität. Der Link nach Wetter schwankt jedoch (laut Gluon) zwischen 0% und 100%.
Diese Schwankung kann ich nicht nachvollziehen: der Link steht stabil, 1000 Pakete im Ping kommen durch.
Kabel bei der SPD stirbt. Wasserschäden, Marder, PIMF mit Knickstelle oder evtl auch das Netzteil.
Kannst Du die remote-NS rebooten wird es erstmal wieder OK sein, Abstände werden aber immer kürzer.
Hatten wir hier schon mehrfach, haben dann erst Netzteil, dann Gluon-AP, dann Nanostation/Litebeam getauscht, und schließlich dann das Kabel.
Hallo Adorfer, besten Dank für die Einschätzung. In dem konkreten Fall könntest du recht haben, dass bei der Gegenstelle ein solches Kabelproblem vorliegt. Das teste ich noch.
Zweifeln lässt mich allerdings, dass ich das Problem ja auch noch bei einem anderen Powerbeam habe. Der ist am selben Standort, allerdings über ein anderes Kabel und an einem anderen ERX. Und diese Installation ist brandneu, inklusive Gen2 Powerbeams und nagelneuer Kabel auf beiden Seiten.
Leider bisher kein Ansatz. Ich halte Kabelprobleme allerdings auch für unwahrscheinlich:
Auch ein ER-X. Die Links kommen über diverse VLANs auf den ER-X.
An einem anderen ER-X ist mir ein Problem aufgefallen, dass vielleicht zusammenhängt:
Hänge ich alle 5 physikalischen Ports einzeln in bat0, findet über bestimmte Ports (bei mir eth3-5) keine Übertragung (oder nur unidirektional) statt. Fasse ich eth3-5 auf einem VLAN zusammen und füge es als gluon_wired hinzu, geht es.
Ich verstehe die Metrik nicht im Meshviewer.
„100% OGM und 0% OGM in die andere Richtung“ richtig?
d.h. „Batman-mesh funktioniert nur unidirektional?“ Dann streiche das Kabelproblem!
Wenn ihr da ein Vlan-Setup habt, dann habt ihr das Tagging vergurkt, das ist mir unter Openwrt auch schon passiert in einem Futro-MultiVLAN-Setup, um Client-Isolation (besser: Linkstrecken-Isolation) hinzubekommen, um keine Phantom-Links auf die Community-Karte zu projezieren.
Da hilft nur TCP-dumpen!
Oder Leute mit gutem Abstraktionsvermögen, wenn Du irgendwo halbwegs lesbar den Inhalt von /etc/config/network verlinkst der betroffenen ERX(?)-Gluons.
Ist eigentlich die Frage geklärt, ob es sich um ein real existierendes Problem handelt, also ob die Verbindung tatsäch gestört ist?
Ich kann bestätigen, dass zumindest Pings von beiden Seiten der Linkstrecke aus durchkommen. Traceroute6 bestätigt, dass es nur ein Hop ist. Die Laufzeit liegt bei 1-3ms, von daher können wir auch einen VPN Mesh ausschließen. 0% packet loss.
Ich kann bestätigen, dass batctl ping <$gegenüberliegender_node> über die Funkbrücke funktioniert:
> batctl ping 2a03:2260:3013:200:f29f:c2ff:fe65:1715
PING 2a03:2260:3013:200:f29f:c2ff:fe65:1715 (4a:29:09:85:36:23) 20(48) bytes of data
20 bytes from 2a03:2260:3013:200:f29f:c2ff:fe65:1715 icmp_seq=1 ttl=50 time=1.74 ms
20 bytes from 2a03:2260:3013:200:f29f:c2ff:fe65:1715 icmp_seq=2 ttl=50 time=1.94 ms
20 bytes from 2a03:2260:3013:200:f29f:c2ff:fe65:1715 icmp_seq=3 ttl=50 time=1.24 ms
Außerdem kann ich bestätigen, dass beide ERXe in der Tat Link Isolation über VLAN haben.
Unter /etc/config/network haben die ERX Ports auf beiden Seiten eine VLAN ID zugewiesen bekommen.
Auf einer Seite wird darüber hinaus auch getaggtes VLAN ausgegeben, um das Management Interface der Bridges mit einer Client IP zu versorgen.
Ich bin jetzt schon soweit, mir einen Laboraufbau zu machen und wirklich tcpdump an den Start zu bringen. Wer noch einen zeitschonenderen Ansatz hat, darf mir gerne auf die Sprünge helfen
Bei diesem Knoten gibt es alternative Wege für etwaige Rückrouten. Bei einem anderen Standort sind die angeschlossenen Knoten offline, daher gibt es nur die eine Sicht (die anderen können ja nicht melden). Ich kann nicht ganz ausschließen, dass es dort ein anderes Problem ist. Es sieht mir aber verdächtig ähnlich aus.
Ich verstehe die Frage nach dem „Warum“ nicht.
Hinterfragst Du damit den Sinn der Möglichkeit, dass Konfigurationsfehler in diesem Universum prinzipiell existieren können sollen?
Oder möchtest sagen „ich kenne solche Vlan-tagging-Probleme noch nicht“?
Mikrotik hat als Ausweg aus solchen Szenarien so eine „Windows-Administrator-Strategie“ im Angebot für die Switchports: „so lange herumprobieren, bis es nicht mehr kaputt aussieht“:
vlan-mode: disabled, enabled, optional, strict, secure, always strip, add-if-missing, leave-as-is (habe jetzt bestimmt noch welche vergessen…)
P.S. @CaptainAndi Ich würde mich in der Installation zuerst auf die Suche nach einem „Smartswitch“ von TP-Link machen.
Mir ist tatsächlich noch nie ein Problem begegnet, wo ein falsches VLAN-Tagging zu unidirektionalen Verbindungen führt. Die Möglichkeit scheint mir auch nicht schlüssig zu sein: Egal wie man es vermurkst, die Verbindungsendpunkte verstehen sich einfach nicht mehr, in beiden Richtungen. Entweder ist da ein unerwarteter VLAN-EtherType, eine andere VLAN-ID oder ein anderer EtherType wo ein VLAN erwartet wird. Wie soll man ein VLAN-Tagging denn verbiegen können, dass Daten in nur einer Richtung verlässlich durchgehen?!
Versteht mich bitte nicht falsch: Ich will es nicht ausschließen. Ich sehe die Möglichkeit tatsächlich nicht. Eine Erklärung oder die Beschreibung eines Szenarios lese ich gerne. (etwas OT, aber was solls…)
Zum eigentlichen Problem:
Ein Ubiquiti AC-Mesh mit gluon und MoW, angeschlossen auf Port 3 eines ER-X mit gluon und folgender Konfiguration (Ausschnitt):
Was Openwrt anbelangt: ich habe bei einem Futro (sendet auf n batman-interfaces, auf ein getagges eth) in Verbindung mit TP-Link-Smartswitch zum Untaggen auf die verschiedenen Nanobeams irgendwann aufgegeben und den TP-Link durch einen Zyxel-Switch getauscht, damit war der Spuk der „nur auf der Karte unidirektionen Links“ dann vorbei. Evtl. habe ich natürlich nur die PVID pro Port nicht syncron mit den VLAN-ID-Taggings gegabt. Aber allein die Tatsache, dass man da so kompletten Unsinn konfigurieren kann, ohne gewarnt zu werden: Nur benutzen wenn man sich drauf einlassen will.
ich konnte das Thema lösen - zumindest das skizzierte Problem ist bei mir jetzt gefixt.
Vorab:
Smartswitches oder TP-Link-Devices wie von @adorfer beschrieben, sind in meinem Szenario nicht enthalten. Alles spielt sich in der Ubiquiti Welt ab (Powerbeam, Nanostation 5AC Loco, ERX, AP AC Pros). Die ERXe und AP AC Pros laufen mit Gluon2020.2.2, die Richtfunkgeräte mit Stockfirmware.
Gelerntes:
Das Problem hat nichts mit Richtfunk zu tun, es zeigt sich auch mit kabelgebundenen Verbindungen, bei mir ganz konkret bei einem ERX, der per Kabel an einem AP AC Pro hing.
Das Problem taucht immer dann auf, wenn an einem ERX mehrere Geräte hängen (z.B. AP, Richtfunk, anderer ERX).
Habe auch spaßeshalber mehrere ERXe ausgetauscht und mit „frischer“ Config versehen. Ebenfalls ohne Erfolg.
Die Lösung:
Das 0%-100% konnte ich mit einer zusätzlichen MAC Adresse lösen. D.h., das Interface, auf dem die Probleme auftauchen, muss eine eigene MAC bekommen.
Beispiel:
Du hast einen ERX, der auf eth0.3 ein 0-100 Problem hat. Die MAC Adresse auf deinem WAN Port lautet 18:e8:29:5c:c3:50. Dann ergänze in /etc/config/network:
config device 'brc_device'
option name 'eth0.3'
option macaddr '18:e8:29:5c:c3:51'
Die 1 am Ende der MAC Adresse kommt daher, weil du eine individuelle MAC Adresse willst. Letztlich wird hier einfach willkürlich hochgezählt, basierend von der MAC des WAN Ports.
Der Name „brc_device“ ist ebenfalls willkürlich. Falls du auf einem ERX mehrere Ports mit Problemen hast, bietet es sich an, hier ein besseres Namensschema zu nehmen. Zum Beispiel „brc_eth3“. Dann musst du mehrere von diesen brc_device Einträgen in der Config hinterlegen - jeweils ein Eintrag pro Problemport.