Eben genau nicht ARP, lies nochmal nach.
Hallo.
Ich beobachte das gleiche Phänomen. Wir versorgen hier die Liegewiese eines Freibads u.a. mit 3 NSM Locos, 2 mit xm und 1 mit xw Hardware.
Mit 2017.1.x kamen die xm-Locos erst bei >70 Clients aus dem Tritt, mit der 2018.2.1 bereits ab ca. 30-40. Die xw-Loco macht aufgrund des größeren RAM erst ab ca. 60 Clients Probleme.
Ich habe auf allen dreien logread -f mitlaufen lassen, in fast allen Fällen bekomme ich vor dem Reboot keine Fehlermeldung. In einem einzigen Fall konnte ich folgendes mitschneiden:
Tue Jun 25 14:24:00 2019 daemon.info hostapd: client0: STA 24:18:1d:a5:f1:df IEEE 802.11: authenticated
Tue Jun 25 14:24:00 2019 daemon.info hostapd: client0: STA 24:18:1d:a5:f1:df IEEE 802.11: authenticated
Tue Jun 25 14:24:00 2019 daemon.info hostapd: client0: STA 24:18:1d:a5:f1:df IEEE 802.11: associated (aid 18)
Tue Jun 25 14:24:00 2019 daemon.notice hostapd: client0: AP-STA-CONNECTED 24:18:1d:a5:f1:df
Tue Jun 25 14:24:00 2019 kern.info kernel: [75504.475761] do_page_fault(): sending SIGSEGV to odhcp6c for invalid read access from 0000002c
Tue Jun 25 14:24:00 2019 kern.info kernel: [75504.484592] epc = 0040451d in odhcp6c[400000+8000]
Tue Jun 25 14:24:00 2019 kern.info kernel: [75504.489724] ra = 004044e9 in odhcp6c[400000+8000]
Tue Jun 25 14:24:00 2019 daemon.notice netifd: Interface 'client' has lost the connection
Tue Jun 25 14:24:01 2019 daemon.warn dnsmasq[706]: no servers found in /tmp/resolv.conf.auto, will retry
Tue Jun 25 14:24:01 2019 daemon.info hostapd: client0: STA 00:b5:d0:ea:4f:af IEEE 802.11: authenticated
Tue Jun 25 14:24:01 2019 daemon.info hostapd: client0: STA 00:b5:d0:ea:4f:af IEEE 802.11: associated (aid 66)
Tue Jun 25 14:24:01 2019 daemon.notice hostapd: client0: AP-STA-CONNECTED 00:b5:d0:ea:4f:af
ssh: Connection to root@2a03:2260:120:300:6a72:51ff:fe44:834b:22 exited: Error reading: Connection reset by peer
Vielleicht ist die Fehlermeldung hilfreich.
P.S.: der 1043er im Kiosk schmiert nun auch ab ca. 30 Clients einmal pro Stunde mit plötzlich vollaufendem Speicher ab. Alle o.g. Geräte hängen an einem Offloader und Wlan-Mesh ist zur Zeit deaktiviert. In der lokalen Wolke sind insges. ca. 200 Clients.
Wir haben auch auf vielen Nodes ab circa 30-40 Clients reboots.
Hier im Moment sehr prominente Beispiele:
https://map.ffmuc.net/#!/en/map/60e327edfb5a
https://map.ffmuc.net/#!/en/map/98ded0a79164
https://map.ffmuc.net/#!/en/map/68725132e37f
Auch hier keine Fehler im logread -f die Nodes sind aber auf einmal weg und kommen dann wieder.
Das ist schön, wie sich hier Meldungen sammeln, ich wünsche mir aber mehr Beteiligung im Upstream Bugreport, damit wir das Problem weiter eingrenzen können.
Dafür sind zum jetzigen Zeitpunkt Beobachtungen in dmesg und logread, sowie Muster in den betroffenen Geräte, Chipsätzen, usw. überaus hilfreich.
Ich Stimme Dir zu, allerdings bin ich da noch etwas ungeübt. Software backen und aus meiner beruflichen Tätigkeit in Sachen IT Infrastruktur kenne ich Die Layer 2/3 problematiken.
BATMAN / fastd usw. Sind für mich auch Neuland.
Geht schon los, das ich es bisher noch nicht hinbekomme habe, einen eigenen. Supernode zum testen aufzusetzen.
Taste mich da langsam ran.
Nutze daher gerne hier das Forum um mich weiter nach vorne zu bringen…
EDIT: Hab gesehen das du das gemacht hast. Danke
Hallo.
Wie stellst du bei dir fest dass es der respondd ist?
Ich hatte hier heute testweise auf einer Loco den respondd deaktiviert, aber auch auf dieser ist plötzlich innerhalb von ca. 5 Minuten der Speicher vollgelaufen bis sie sich selbst neu gestartet hat.
Das das ist offensichtlich (siehe Diskussion am Gluon-Issue) alles nur noch das Symptom der „Todesspirale“: respondd-Meldungen, hohe Prozessorlast, ebtables-messages.
Da der Spuk offensichtlich bei Erreichen einer bestimmten Wifi-Client-Zahl auftritt (bei wired-clients nicht) und mit einem einzigen (rechtzeitig eingetippten) „wifi<enter“ kurzfristig beendet werden kann:
Derzeitige Vermutung ist, dass ein Speicherleck im im Wifi-Treiber selbst besteht. (oder hypothetisch auch im Batman, falls der schlicht durch durch die „herausfallenden Wifi-Clients“ auch dort Tabellen gerade noch rechtzeitig reorganisiert. Allerding eher unwahrscheinlich, weil eben wired-clients das Problem nicht zu verursachen scheinen.)
Ich habe das Problem bisher tatsächlich nicht beobachtet (oder einfach nicht bemerkt).
Überall wo wir aktuelle Firmware haben, verwenden wir Tunneldigger (L2TP), vielleicht ist das Problem nur auf Nodes mit Crypto so deutlich vertreten?
Alle auffälligen Knoten hier werden per Kabelmesh versorgt und haben mit Crypto nichts am Hut.
Unsere größten Sorgenkinder aktuell
https://map-hemer.freifunk-mk.de/#!v:m;n:68725144834b
und
https://map-hemer.freifunk-mk.de/#!v:m;n:c46e1fc9c410
Es scheinen am ehesten die Knoten betroffen zu sein, an denen viele An- und Abmeldungen per Wlan passieren. Dort wo viele Leute über längere Zeit fest eingeloggt sind und nur friedlich Daten saugen scheint die Situation weniger kritisch zu sein.
Ich werde mal die Statistiken prüfen aber ich glaube die Orte die ich bewirtschafte, sind relativ dicht versorgt, haben also eine gute Verteilung. Das höchste bisher waren 35 Clients an einer Nano M2 (2018.2.1), allerdings kein Reboot, dafür ständig wechselnde Clients.
Kabelmesh habe ich nirgends, alle Nodes haben WAN/LAN-Mesh aus, lediglich 11s-Mesh und VPN an.
Kann man das Problem mit Tools unter Linux provozieren, also Fake-Clients erzeugen? Dann kann ich das gerne mal untersuchen.
Mich würde aktuell insbesondere interessieren, ob ihr das Verhalten (Memory leak bis reboot ab ~40 Clients) auch bei anderen Geräten, die nicht ar71xx/ath79 sind, seht.
Könnt ihr euch da mal in euren Communities umsehen?
Gerüchteweise haben Leute hier größere Kisten mit 841ern. Falls also jemand einen halbwegs intelligenten Clientsimulator als factory-image für 841v9-11 bauen mag, die man da per PushbuttonTFTP drauf bringt und vollautomatisch ins nächstbeste „Freifunk“ einbucht und loslegt.
Ich habe keine genaue Vorstellung davon was so ein Handy im Netz tut und was realistische Last ist, aber ich denke mal
-
reichlich DNS zu CDNs (aws, fastly, cloudflare)
-
reichlich offene TCP-connects für „Push-Dienste“
Dieser Transportcontent wird einen Batman-Knoten jetzt eher weniger stressen (evtl. einen lokalen dnsmasq-proxy, aber der ist hier wohl nicht in Verdacht) -
häufige connects/disconnects, evtl. „low-power-keepalives“, was immer Handies so tun um im Halbschlaf Strom zu sparen und nur ab und an bei Whatsapp&Co nach neuen Nachrichten zu schauen.
(Wenn man also so 50 Stück 841er „aus dem Verkehr gezogen hätte für eine Testbench“, wo immer das dann hingestellt würde, dann würde das bestimmt Leute freuen… Auf eine Wand gedübelt könnte man fast ein Matelight draus machen… Toppoint anyone?)
Offtopic: Na da haste doch ne Verwendung für dann ![]()
Wir haben einen CPE2.0 im Freibad, bei dem das nachvollziehbar ist.
Ab ca 35 Clients, steigt nach ca 12 Min die Speicherauslastung an und der Knoten rebootet dann bei irgendwas über 75% Speicherauslastung.
Ein Downgrade von 2018.2.1 auf 2017.1.8 brachte nichts.
dmesg zeigt nichts. Genausowenig gibt es Einträge im syslog.
Mit top seh ich nichts auffälliges - außer dass der freie Speicher dann von ca 33 MB zu dem genannten Zeitpunkt rapide runtergeht und bei ca 10MB rebootet er dann:
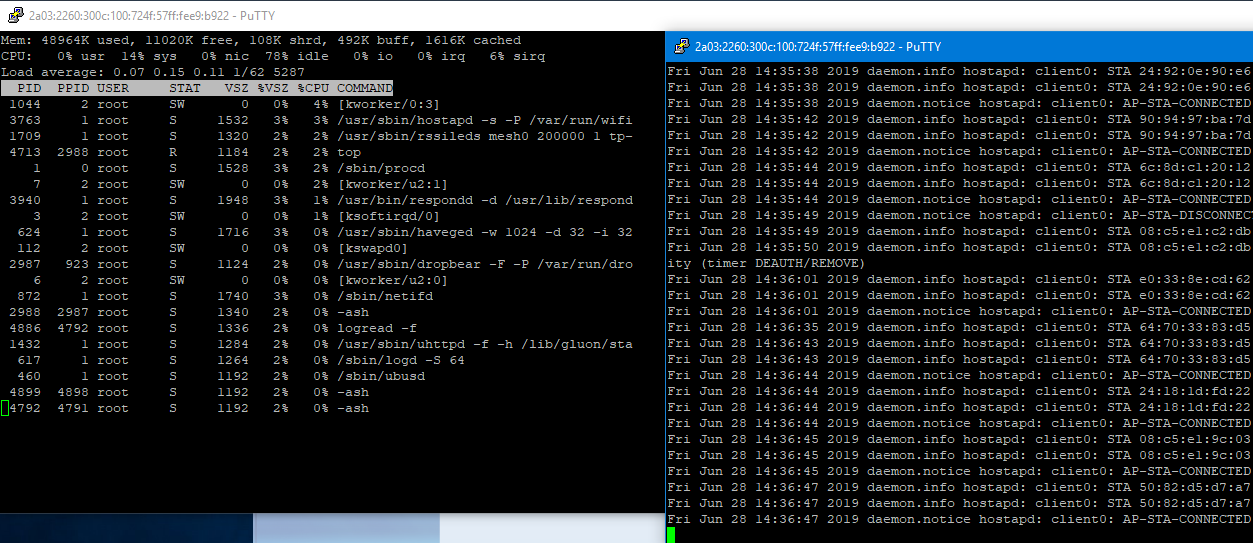
Kann ich sonst noch irgendwelche nützlichen Infos beisteuern. ?
Ah, der Knoten macht macht vpn mit tunneldigger und hat keine mesh Nachbarn.
Ein wifi-restart gibt den Speicher wieder frei und der Knoten läuft wieder 10-15 Min mit konstantem Speicher (auch bei 50 Clients) bis es dann mit dem Speicherverbrauch wieder steil bergauf geht.
Du müsstest auf Gluon 2016.2 runter, aber das wird natürlich nix, weil da die CPE210v2 noch nicht drin war.
Jep. Das war auch mein erster Gedanke, bis ich feststellen musste dass es den da noch nicht gab. ![]()
Wenn ich mit irgendwelchen Logs zur Fehlereingrenzung was beisteuern kann, sagt Bescheid.
Die Diskussion läuft im Gluon-Issue plus IRC. Es scheint wirklich voranzugehen, der Suchradius nach dem Bug wird dem Anschein nach immer kleiner. Will sagen: Es besteht Grund zur Hoffnung.
Mithilfe benötigt!
Gemäß Gluon Issue
Issue: ath9k devices run out of memory above certain client count
ist derzeit der Stand: (man korrigiere mich, wenn ich etwas falsch aufgeschnappt haben sollte.)
-
betrifft ATH9k-Geräte (nicht Mediatek oder IPQ) ab Gluon 2017.x (inkl. 2018.2 und master)
-
wenn Clientcount einen (noch nicht näher gefundenen) Wert übersteigt „kippt“ irgendetwas, ab dann verliert der der Router eine ziemlich konstante Menge von MB Ram pro Minute, bis der Speicher so knapp wird, dass a) die Last wegen einsetzenden Swappings ansteigt und b) irgendwelche Prozesse gar nicht mehr starten können (ebtables-Update) aus Ram-Mangel c) final ein Panik-Reboot erfolgt
-
Es gibt zahlreiche Debug-Optionen die zum Testen mit in Openwrt/Kernel eincompiliert werden müssen um detailliertere Logs zu bekommen als derzeit vorliegen
-
Die Debug-Optionen verlangsamen den Router so arg, dass er kaum noch real nutzbar ist und die „magische Client-Anzahl“ in normalen Produktionsumgebungen gar nicht realistisch erreicht werden kann, weil die Clients schon vorher „aus Frust über unsäglich langsames Freifunk“ wieder ins Mobilnetz zurückwechseln. Ausserdem ist wohl ab und an eine serielle Konsole notwendig, um überhaupt noch etwas mitzubekommen.
-
Es Bedarf also akut an Leuten, die
- Firmware compilieren mögen mit diversen vorgeschlagenen Kernel-Options und/oder patches
- mit einem zweiten halbwegs leistungsfähigen Router STA-Emulation (also Clients vorgaukeln)
- Debuglogs ziehen/filtern, also Informationsverdichtung betreiben mögen.