Gibt es hier auch Mitglieder, welche durch Einsatz der neuen gluon 2018.2.1 häufige Reboots bei stark ausgelasteten Mesh-VPN Knoten feststellen ?
Aufgefallen bei 1043er v2 841er v9-13 und CPE210 (alle)
Wie kann ich ein vernünftiges Load balancing realisieren ? Einfach einen. 2ten Knoten (auch durch anderen Kanal) funktioniert nicht.
Max_clients oder so als config einfügen?
Geht das ?
Also das Problem tritt ein, wenn ein fastd VPN knoten mit weit über 60 Clients bombardiert wird.
Dann geht die CPU Last auf dem Knoten auf 100% (RAM Auslastung 50-60%) und Reboot…
Folglich wird er nach dem hochkommen. Wieder mit so vielen Anfragen konfrontiert und das Spiel beginnt von neuem…
Verbunden ist er mit nur einem Supernode …
Ich meine mit der 2017 war das Phänomen nicht.
Zumindest hatten die uptimes von mehreren Tagen (trotz der Lasten)
Um es sicherheitshalber festzuhalten: Es geht also explizit um 64MB-RAM-Geräte, korrekt?
Gegen welche Firmware vergleichst Du wenn Du sagst „war vorher nicht so“?
Und ihr habt nicht zufällig da ein Modul aktiv, was Knoten bei „dauerhaft hoher Last“ automatisch neu startet? Solche habe ich mal unter 2017.x gegesehen, die wurden genutzt um Knoten aus der „Todesspirale“ des Speicherdrucks zu befreien.
Die Geräte sind einfach zu schwach für so eine Belastung. Häng entweder einen Ubiquiti-AP mit Originalfirmware dahinter und nutze den 841er nur für Mesch oder ersetze ihn durch ein leistungsstärkeres Gerät.
Es bringt vor allem nichts, selbst wenn die CPE210 oder der 1043er nicht in Panik rebootet: Wenn irgendwo mehr als 30 clients drauf sind, dann ist der AP nur noch damit beschäftigt, alle im Netz online zu halten und die v6-Neighbor-Discoveries und anderweitige Broadcasts herumzusenden. Nutztraffic ist dann nicht mehr sinnvoll möglich, auch wenn’s auf der Karte vielleicht toll ausschaut mit den vielen Punkten am Knoten.
(Ist aber ein anderes Thema…)
Das ist für mich die letzte Option:
„Edgerouter X“ als VPN ubd einen AP mit Stock dran…
Nur trifft es auch die Nanos…
Selbes Phänomen.
Respondd frisst ab >35 Clients den Speicher auf
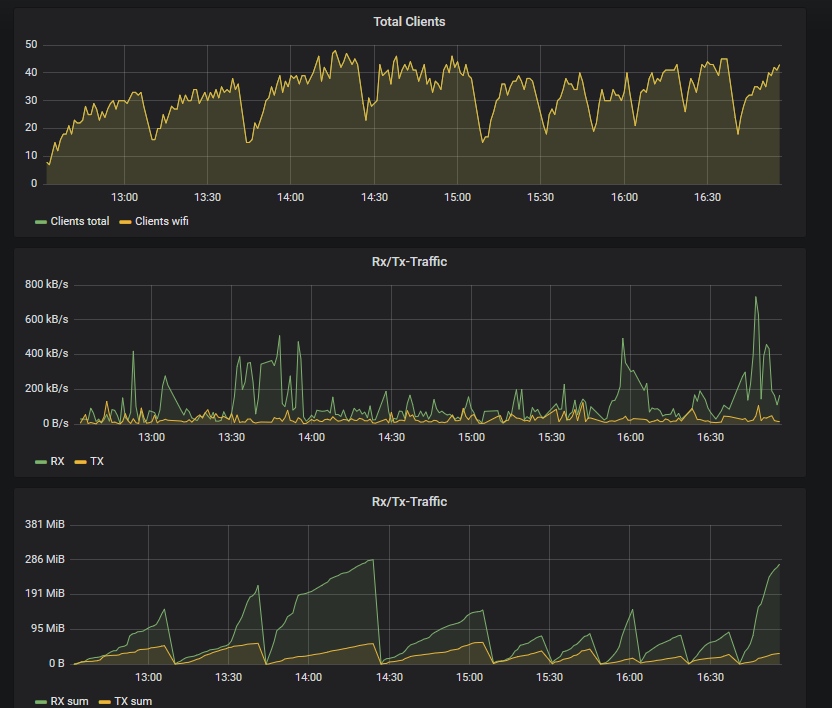
So, haber das Problem mal genauer beobachtet (aktuell sehr schön zu sehen , da ich einen CPE v1.1 als Freifunk AP bei uns im Kulturzelt aufgebaut habe)
Szenario 2: LTE Router → UBNT Edge Router X mit 2018.2.1 (ohne Custom Patches, 1Supernode fastd) -MOL-> CPE 210 (wie oben)
Auslastung UBNT ERX <20%
Auslastung CPE ~50 %
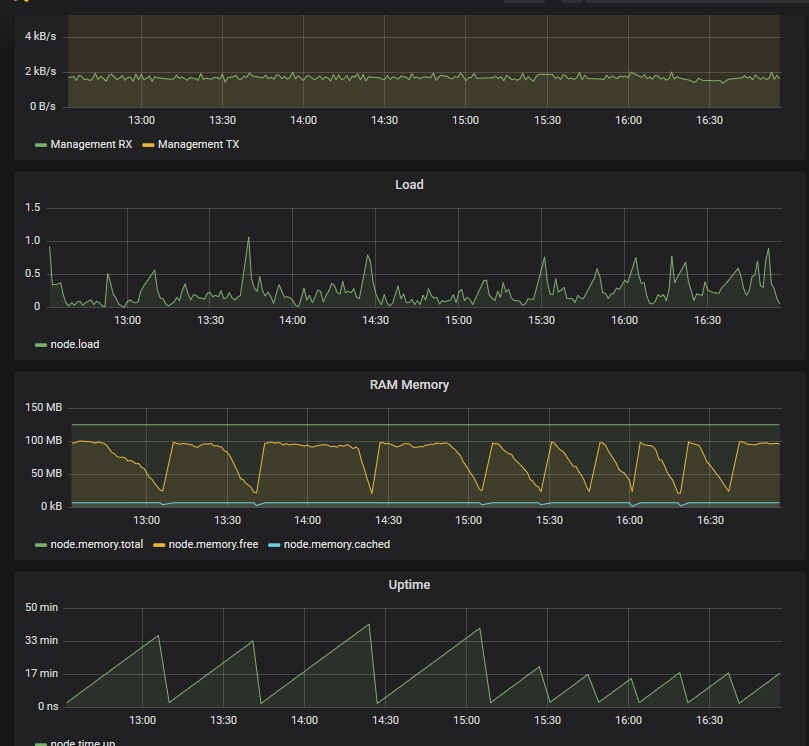
…läuft eine weile (auch mit >35 Clients), dann irgendwann nach vielen an-/abmeldungen (laut logread) schiesst der RAM Verbrauch innerhalb von wenigen Sekunden nach oben —> OOM Kernel Panic (CPE)
Der ERX läuft gechillt weiter…
Immer respondd, was den Speicher auffrist.
Morgen hänge ihc mal eine CPE mit Stock FW auf und Lasse den UBNT ERX das FF-Netz bereit stellen… (habe dann zwar kein Mesh, ist aber als „Testobjekt“ zu sehen, ob der ERX dann auch zu kämpfen hat)
Das dürfte in vielen Freifunk-Communities keine valide Option sein, weil dann nicht über Funk gemescht werden kann.
Der hat auch 256 MB RAM im Vergleich zu den 32 MB der 841er.
Streng genommen könntest du respondd auch einfach abschalten. Dann sind die Router halt Karteileichen auf der Karte. Aber besser als wenn das Netz nicht nutzbar ist.
Ich liebe diese „Dark-Nodes“… Aber man soll ja nie Vorsatz unterstellen.
Aber wenn man mal so schaut wie das Verhältnis zu batman-Knoten zu Map-Knoten ist, da bekommt man doch schon Stirnrunzeln. (Ja, ich weiss, dass interne Server/Supernodes ohne accounce-Tool auch „dunkel“ sind für Map)
Aber ganzu nur Not gibt es ja noch den „Graph der alten Schule“.
Es Betrifft auch die Nanostation, CPEs und 1043er.
Die haben 64MB oder nicht ?
Wir haben einen 941er mit 2016.2 laufen der muss teilweise >70 CLients fassen , der macht allerdingskein reboot… (Klar Nutzbare Bandbreite ist da nicht mehr viel aber er bleibt am leben und läuft eben nicht durch ein OOM)
RAM-Auslastung ist bei dem ~85-90% bei >70 Clients
und das macht mich so stutzig
Und klar, kann man an den ERX ein Mesh über ein sep. Port und eigenen AP (der eben nur WIFI MESHed) dran hängen . haben wir auch einige
Sorry, ich hab das erst abends in Grafana gesehen als alles längst durch war.
Da aber respondd noch bis zu letzt Daten meldet, denke ich am network-stack geht noch bis zum Schluss alles durch.
Ich komme an das Ding höchstens per SSH dran. Ich werde mal das mesh-radio0 und 1 aus machen und hoffen, dass das Schwimmbad wieder voll wird. Dann schau ich per SSH auf das logread.
Hat jemand ein Skript, was per Webhook bei nem Trigger Infos von logread raus hauen kann? Dann bekomme ich ne Info auf Telegram wenn es los geht.
So, hat geklappt. Rebootet aktuell wieder mehrfach nach RAM-Mangel. Der Logread-Mitschnitt ist hier:
Grafana sagt ab ca. 16:15 geht das freie RAM kontinuierlich zurück. https://pastebin.com/xpix93ik
Eine spannende Frage wäre: Ist der Knoten in dem Moment wo der ebtable-arp-limiter seine batctl-calls nimmer durchbekommt bereits in der Todesspirale und die vielen fehschlagenden Calls sind nur noch ein Symptom oder sorgt die davon verursachte Last dafür, dass das System final abkippt.
ARP, ja das dachte ich mir auch schon.
Gerade weil es dann auftritt, wenn viele An-/Abmeldungen erfolgen. Die Einträge müssen ja erst TTL erreichen, bis sie raus geworfen werden.
Ich denke mal, das mangels Ram , batctl nicht mehr aufgerufen werden kann.
Oder es ist der Limiter an sich…
Weil ich ja sagte, bei 2017.1.x hatten wir die Probleme nicht (Gleiche Hartdware / Gleicher Standort)