Moin ich möchte heute mein Wochen Projekt vorstellen. Hierbei handelt sich um ein etwas größer klingendendes Projekt, als es eigentlich war (4Tage bis zur v0.1.0). Ich habe in meiner Freizeit eine Suchmaschine für das Freifunk gebaut. Diese ist noch nicht annähernd fertig aber sie „funktioniert schonmal“.
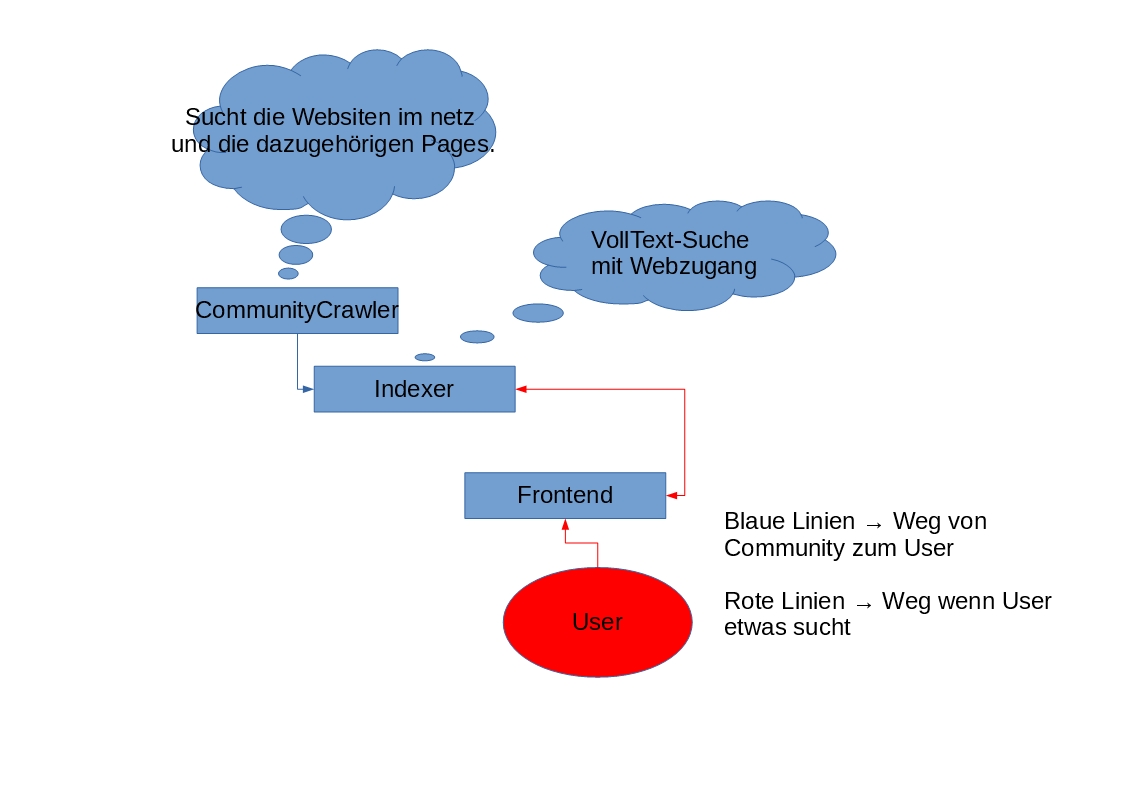
Der Community Crawler - Dieser Scannt das netz nach offenen Ports welche danach nach HTTP Seiten durchforstet werden und Anschließend als Paket an den Indexer zum indexieren gesendet werden
Der Indexer - Das Herz des ganzen könnte man sagen. Dies ist kurz gesagt einfach eine VollText-Suche welche einen HTTP Endpunkt zum erhalten der Community Crawler und einen zum abrufen der Daten.
Das User Interface - Hier ist nichts besonderes. Aktuell ist es ein Suchfeld mit der Möglichkeit die Community, die man nach dem Begriff durchsuchen will, auszuwählen.
Der Community Crawler wird wie der Name bereits sagt in den teilnehmenden Communities installiert (vorzugsweise Communities mit ICVPN). Der Indexer und das Frontend können sowohl in den jeweiligen Communities als auch zentral installiert werden. (Der Community Crawler unterstützt senden an mehrere Indexer)
Weitere Ideen/TODO
Das ganze ins ICVPN hosten (aus dem Netz ffslfl wird dies zukünftig passieren)
Reverse Anfrage an die Community DNS um den Domain Namen zu erhalten wenn vorhanden
Aus der Freifunk API Daten wie Kalender und Feeds erhalten
Erkennung auch von anderen Softwaren, wie Jabber, Minecraft, Mumble, etc.
weitere Ideen gerne in die Kommentare!
Technische Umsetzung (Stand: 4.1.18)
Beide Backend Anwendungen sind in Golang geschrieben und somit Plattform unabhängig. Das Frontend ist in Angular2 geschrieben.
Die Crawler sind zudem blockbar durch eine robots.txt der Crawler name dafür ist: „FreifunkSearchProjektCrawler“. Zusätzlich crawlt der nur auf der selben Seite und nicht bei Links die von den Seiten wegführen. Dies liegt einfach dadran, dass ich nicht vorhabe das Internet zu indexieren ^^
Hintergrund wieso ich dies baue
Ich fand es schon immer nicht Enduser freundlich eine WIki mit einer IP Liste zu haben. Natürlich sehe ich da wieso dies gemacht wird (es ist halt einfach einfacher). Jedoch bietet die Suchmaschine viel mehr Freiheiten. Zudem weiß ich das es sehrwohl bereits nutzbare Suchmaschinen gibt. Diese funktionieren allerdings meiner Meinung nach nicht besonders gut im ICVPN. Man müsste für jede Community erst einmal die ip der suchmaschine finden bevor man suchen kann im Netz. Mein Ziel hier ist es zu zentralisieren aber zugleich die Möglichkeit geben es lokal anzubieten (deshalb lassen sich Frontend und Indexer selbsthosten). Mit der Software hat man zum einem viel einfacher nach zum Beispiel „Podcast“ zu suchen und vielleicht im ICVPN podcasts zu finden zum anderen ist es für „Nicht-Nerds“ einfacherer eine Suchmaschine zu nutzen, als eine Wiki zu durchforsten. Zudem erhoffe ich mir, dass dies die Freifunk Idee von Internen Diensten fördert.
Ich hatte damals eine ähnliche Idee gehabt, hätte das ganze aber mit Standardisierung „erschlagen“. Ich hätte einen gewissen Port definiert auf dem man einen httpd laufen lassen sollte, der unter einer gewissen URL (evtl auch einfach robots.txt) eine Beschreibung der auf dieser IP gehosteten Services (Dienst + Port) hinterlässt, die man dann automatisiert auslesen und vielleicht auch monitoren könnte.
Wie hast du das Scanning umgesetzt? Standard-SYN-Scans wie Standard-nmap?
Da muss ich tatsächlich nachgucken. Ich habe mich für den Anfang für den simpelsten Weg entschieden und vorhandene Libaries verwendet. In dem Fall handelt sich es um: GitHub - anvie/port-scanner: Simple port scanner library for Go
Diese prüft ledeglich ob es auf TCP eine Antwort gibt und merkt sich das. Der Punkt dem auch zu vertrauen was genau da läuft habe ich aktuell noch nicht implementiert. (Hast mich aber gut drauf hingewiesen. Ich hätte es vergessen). Die Libary könnte soweit ich es sehe diese Ports als default Ports erkennen und HTTP auch aufgrund von einer HEAD anfrage.
Gibt aktuell weder eine gehostete Version noch eine Rangliste Die Idee finde ich jedoch gut eine Rangliste zu bauen ^^ Das Projekt ist wie im Text genannt gerade mal ca 4 Tage alt Ich habe gerade erst geschafft das zum halbwegs laufen zu bekommen. Ich habe aber es vor so schnell wie möglich auf einen Server zu bringen und ins Freifunk Schleswig-Flensburg
Man findet ziemliche viele Streaming-Clients und einige offene NAS.
Da lohnt sich das indizieren, insbesondere wenn dort Filme/Serien liegen.
Ansonsten klingt es so ein wenig nach dem Versuch, yacy in der Geschmacksrichtung shodan neu zu erfinden.
Ich vermute, dass der eine oder die andere darüber gar nicht glücklich sein wird.
Ich habe erstmal vor hauptsächlich HTTP zu indexieren, dann Termine und Feeds, sowie Chat Server listen. Natürlich will ich nicht jeden Einzelnen PC mit Port angaben indexieren wie es Shodan macht
Die Idee eine Suchmaschine für Dienste im Freifunk zu bauen ist an sich schon ziemlich klasse aber was mir noch besser gefällt ist das das ganze auch verteilt funktioniert. Das bringt mich natürlich wieder mal auf ganz böse Ideen. Die Suchmaschine brauch ja damit das richtig rund wird einen DNS Eintrag. Da sich aber auch eine lokale Instanz betreiben lässt die mit anderen Instanzen ihre Datensätze synchronisieren kann würde der ein oder andere das villeicht gerne tun. Idealerweise meldet sich in dem Fall die lokale Suchmaschine unter der IP der Zentralinstanz. Ja, damit trete ich die Netzneutralität wieder mal in den Eimer zugunsten von Performance. Damit das klappt muss man natürlich diese IP im Clientnetz isolieren weil man ansonsten die ARP Tabellen mit inkonsistenten Einträgen vollmüllt.
Das lässt sich auch jetzt schon machen ist aber nicht updatefest.
Falls das Projekt irgendwann weiter ist wäre interessant ob für eine lokale Instanz beispielsweise eine Fujitsu Futro S900 (Sempron 1200, bis zu 8 GB Ram) ausreichen würde. Dank UEFI lässt sich damit eine 4TB Notebookplatte betreiben.
Du möchtest Arptabellen in permanenten Speicher wegschreiben und über Updates hinweg behalten?
Also nochmal zurück:
Was möchtet Ihr mit diesem Ding erreichen?
a) Was soll in der Datenbank realistisch (heute) indiziert werden
b) Wer sind die potentiellen Nutzenden dieser Suchmaschine
c) Auf welchem Wege sollen die Nutzenden Zugang zu diesen Suchmaschine finden.
Mein Posting zum Thema „yacy“ weiter oben im Thread war kein Zufall.
In Frankfurt/Main haben wir das viele, viele Monate lang getan und zu promoten versucht.
Auch zur Unterstützung noch an verschiedenen Stellen ein paar Seafile-Instanzen ins Netz gehängt.
Die Dortmunder hatten da mal ein verteiltes Wiki.
Allein die Tatsache, dass sich hier offensichtlich nur noch wenige daran erinnern können, sagt mir, dass es zwar ein schönes Gedankenexperiment ist bei dem man auch sicher Dinge lernen kann.
Aber einen realen Nutzen generiert man damit nicht.
Naja, mit dieser Betrachtungsweise wuerde Freifunk auch nur begrenzten realen Nutzen generieren, ins Internet, das duerfte der Hauptanteil der Freifunknutzung sein, kann man auch ohne Freifunk und das schon laenger.
Ich verstehe die Aussage nicht, da setzt sich jemand hin, programmiert und dann wird ihm klargemacht, dass das fuer’n Arsch war. Motivationsweltmeister wirst Du sicher nicht @adorfer, dass die Suchmaschine das Freifunknetz nicht neu erfinden wird duerfte dem Threadstarter auch so klar sein.
Ist das nicht gerade eine der Ideen hinter Freifunk? Ist da nicht eine grosse Portion Selbstzweck am Start und ist das denn nicht auch gut so? Spielwiese fuer (neue) Technologien.
Ob es „für den Arsch“ ist oder nicht: Keine Ahnung, diese Wortwahl stammt von Dir.
Ich möchte lediglich den Zweck hinterfragen.
(Und ja, ich mache mir in der Tat über den Arp-Traffic beim Durchsuchen von ganzen IPv6-Prefixen und die mögliche Brisanz bei evtl. unabsichtlich offenenstehenden „Angeboten“ Gedanken. Zu vermuten wäre, dass man die Ergebnisse der Suchmaschine primär dazu nutzen könnte, Menschen davon zu überzeugen, Konfigurationsunfälle zu fixen.)
Nein, ich möchte natürlich keine statischen ARP Tabellen.
Ich möchte nur verhindern das wenn ich einen Dienst lokal betreibe unter einer IP unter der er auch an anderer Stelle betrieben wird die damit verbundenen Störungen auftreten vor denen auch im WiKi gewarnt wird.
Soweit ich ihn verstanden habe erwischt es zunächst alles was Port 80 offen hat, also Rechner bei denen das absicht ist, CCTV und einige Drucker. Daher seh ich da noch kein so großes Problem.
Wenn man sich auf Batman-Netze beschränkt (nur die MACs der batctl tl), dann könnte man daraus einen Security-Scanner machen:
Den Usern im Configmode einen Schalter geben
„Benachrichtigen bei sicherheitsrelevanten Problemen:“ „an Heimnetz-Geräten“ und „an lokalen Freifunk-Geräten“
Und dann arbeitet der lokale Plasterouter als Probe/Proxy, um nach Geräten „am gelben Lan“ und „am Wan-Uplink“ nach verwundbaren Geräten (anfällige Firmware und nicht gesperrte Default-Passwörter) zu suchen. Und dann ggf. per Mail Bescheid geben.
Mal davon abgesehen das du/ihr gerade vom Thread thema abschweift mit dem Thema ARP Tabellen, ist der Grund hier, dass wir ein ICVPN haben (im Idealfall). Mir ist Yacy bekannt jedoch wäre mir neu, dass das auch mehrere unabhängige crawler kann die einen Index befüllen oder mehrere. Der Hauptgrund Yacy nicht zu nutzen ist, dass „Freifunk“ nicht ein Netz sondern eine vielzahl von netzen ist die im optimal Fall über VPN unternander erreichbar sein können.
Solange go drauf geht sollte das reichen. Das einzige was Festplattenspeicher benötigt ist eigentlich der Indexer. Der Crawler verbraucht aktuell noch relativ viel RAM beim crawlen um die Daten zu halten bis zum übermitteln, dass wird vermutlich aber so umgebaut, dass ich die Daten direkt an den Indexer sende und damit keinen RAM overhead verursache durch die Websiten.
Paar Daten was der Crawler gerade so verbraucht für eine Webseite:
Ich habe mal eine v0.1.0 getagt Der Crawler crawlt nun Titel, Body, Description (erster p Tag), URL und der Indexer funktioniert auch. Das ist quasi jetzt die Basis Version mit der es losgehen kann
Und direkt hinterher für die Website nen Hotfix ^^ (Footer blieb nicht unten)
Für den Crawler und Indexer bedeuted dies ich indexiere nun auch Feeds und der Crawler ist nun stabil genug zum testen mit ausnahme der Network option. Zudem ist in der Config nun mein test-Indexer eingetragen. Eine gehostete UI wird folgen in den nächsten Tagen. Zudem kürzt der Indexer Server nun Descriptions auf 260 zeichen plus die bis zum nächsten whitespace wenn man die ClientAPI anfragt. Er indexiert die volle Description.
Für die Website/UI gibt es ein etwas besser angepasstes Design, Pagination bei mehr als 10 Objekten pro Seite, Links werden angezeigt, Die Karten sehen besser aus und Funde werden makiert in den Ergebnissen. Wenn es einen Fund gibt(Fragments) wird dieser anstatt der Description verwendet.
Kleineres Update auf den develop Zweig: Ich habe nun mithilfe von JWT Token eine Userverwaltung eingebaut. Bedeutet ich kann die Daten den verschiedenen Communities zuordnen und zudem kann damit niemand der den Token nicht kennt falsche Daten indexieren lassen. Fehlen tut jedoch noch das Frontend.