Stimmt!
Ich kann facebook.com aber aus dem Ruhrgebiet prima erreichen…
Wir sich aller Wahrscheinlichkeit nach um ein IPv6 Routing Problem in der Domäne Möhne handeln.
Eventuell hat sich eine Konfig auf den Supernodes verhakt. Versuche das zeitnah neu zu machen.
1 „Gefällt mir“
Ich hab 7 Beiträge in ein vorhandenes Thema verschoben: Facebook aus FF-Netz schlecht erreichbar
Fast nichts geht! Verbindungen brechen immer wieder auf 0 ein. 18.30, samstag
traceroute to google.de (2a00:1450:4013:c01::5e), 30 hops max
1 2a02:f98:0:26::21 160.238 ms
2 2a03:2260:0:3::1 216.310 ms
3 2001:7f8:8::73e6:0:2 215.157 ms
4 2001:7f8:8:5:0:3b41:0:1 242.418 ms
5 2001:4860::1:0:6e0f 294.720 ms
6 2001:4860::8:0:6400 244.967 ms
7 2001:4860::8:0:67ec 242.706 ms
8 2001:4860::8:0:519e 293.959 ms
9 2001:4860::2:0:8651 241.382 ms
10 2a00:1450:4013:c01::5e 241.335 ms
Traceroute complete: 10 hops, time: 5387 ms
Das ist die Route übers Rheinland Backbone.
Kannst Du noch nen v4 Traceroute machen bitte?
EDIT:
Aber nicht unsere Route, das läuft über eine Querung ins Rheinufer…ich identifiziere den Router und werfe ihn raus…dauert nen Moment…
traceroute to 74.125.136.94 (74.125.136.94), 30 hops max
1 10.53.88.1 (10.53.88.1) 310.626 ms
2 10.53.16.254 (10.53.16.254) 56.252 ms
3 85.88.13.49 (85.88.13.49) 59.559 ms
4 backbone-1-cgn.surfplanet.de (85.88.20.58) 59.705 ms
5 core-sto2-po2.netcologne.de (87.79.16.57) 112.490 ms
6 rtamsix-te33.netcologne.de (87.79.16.235) 65.424 ms
7 78.35.18.6 (78.35.18.6) 68.685 ms
8 209.85.248.92 (209.85.248.92) 70.955 ms
9 209.85.143.75 (209.85.143.75) 71.095 ms
10 209.85.250.33 (209.85.250.33) 75.293 ms
11 216.239.49.36 (216.239.49.36) 74.006 ms
12 *
13 ea-in-f94.1e100.net (74.125.136.94) 74.819 ms
Traceroute complete: 13 hops, time: 5344 ms
und, wir gefällt Dir die Performance im Rheinufer? ![]()
1 „Gefällt mir“
Bin gewillt einen Rheinufer soli einzuführen ![]()
1 „Gefällt mir“
kicher
…ich habe den Router gefunden, nennt sich „luki2“, und ihn geblacklisted.
5 Minuten noch, dann ist er weg:
1 „Gefällt mir“
Hat sich nun alles wieder beruhigt, kannst Du nochmal traceroutes machen?
Fühlt sich nun besser an:
traceroute to 74.125.136.94 (74.125.136.94), 30 hops max
1 10.53.88.1 (10.53.88.1) 40.946 ms
2 10.53.16.254 (10.53.16.254) 70.625 ms
3 85.88.13.49 (85.88.13.49) 73.095 ms
4 backbone-1-cgn.surfplanet.de (85.88.20.58) 76.311 ms
5 core-sto2-po2.netcologne.de (87.79.16.57) 76.453 ms
6 rtamsix-te33.netcologne.de (87.79.16.235) 83.927 ms
7 78.35.18.6 (78.35.18.6) 84.057 ms
8 209.85.248.112 (209.85.248.112) 84.084 ms
9 209.85.143.77 (209.85.143.77) 107.995 ms
10 209.85.254.231 (209.85.254.231) 84.109 ms
11 209.85.251.25 (209.85.251.25) 84.316 ms
12 *
13 ea-in-f94.1e100.net (74.125.136.94) 83.992 ms
Traceroute complete: 13 hops, time: 5396 ms
traceroute to google.de (2a00:1450:4013:c01::5e), 30 hops max
1 2a03:2260:50:1::1 218.355 ms
2 2a02:f98:0:25::1 224.688 ms
3 2001:4dd0:a000:1::a2 217.651 ms
4 2001:4dd0:a2b:45:dc40::c 77.590 ms
5 2001:4dd0:a2b:a8:30::b 77.770 ms
6 2001:4dd0:b2b::20e6:0:0 78.126 ms
7 2001:4860::1:0:87ab 78.159 ms
8 2001:4860::8:0:519f 77.976 ms
9 2001:4860::8:0:519e 217.813 ms
10 2001:4860::2:0:8652 217.852 ms
11 2a00:1450:4013:c01::5e 218.429 ms
Traceroute complete: 11 hops, time: 5408 ms
1 „Gefällt mir“
Keine Namensauflösung möglich in ipv4.
@hammerhead![]() $ ping google.de
$ ping google.de
ping: unknown host google.de
Ipv6:
traceroute to google.de (2a00:1450:4013:c01::5e), 30 hops max
1 2a02:f98:0:26::21 132.352 ms
2 2a03:2260:0:3::1 284.147 ms
3 *
4 2001:7f8:8:5:0:3b41:0:1 285.305 ms
5 2001:4860::1:0:6e0f 285.082 ms
6 2a00:1450:4013:c01::5e 283.371 ms
Traceroute complete: 6 hops, time: 15197 ms
Keine Internetnutzung möglich.
Ich rate mal: ffrg5 und ffrg7 scheinen gestorben zu sein. Das restliche Netz scheint sich inzwischen davon erholte zu haben, und jetzt geht es wieder.
Richtig, in diesem Moment haben wir die Info vom Provider bekommen, dass es sich um einen Hardware Schaden handelt. Der Rest lauft - noch…
Gruß,
Philip
Beide Server sind seit ca. 5 min wieder online.
1 „Gefällt mir“
Kann mal vorkommen, aber die Wiederherstellungszeit war top…
Ausfall von ca. 11:30 Uhr bis 12:15 Uhr. Wenn x << y von y Servern ausfallen, eigentlich verkraftbar. Was man jetzt untersuchen müsste, ist, warum das ganze Netz darunter gelitten hat:
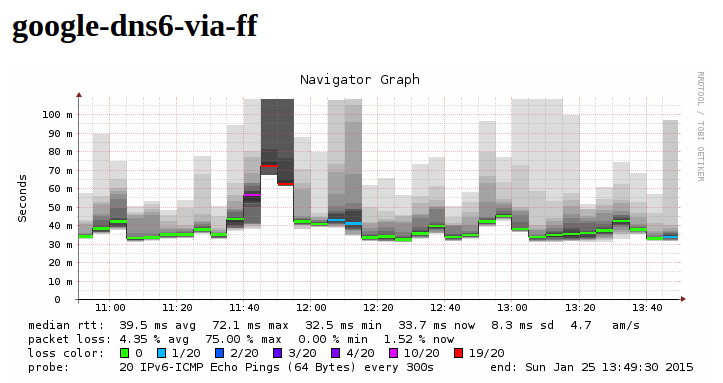
Das raus zu bekommen ist sicherlich nicht die einfachste Arbeit. Jemand einen Ansatz für die Lösung des Rätzels?
Ich habe keine Erklärung finden können, zumal die ausgefallene Hardware rein gar nichts mit dem Internetzugang zu tun hatte.
Heute habe ich unbemerkt das ganze Netz umgebaut.
Alle Server sprechen nun BGP. Über alle Server ist das ICVPN erreichbar.
ffrg0 ist BGP Backbone Gateway, folgende Systeme haben MED Priorität über diesen Weg:
- ffrg6
- ffrg7
- ffrg8
ffrg1 ist BGP Backbone Gateway, folgende Systeme haben MED Priorität über diesen Weg:
- ffrg2
- ffrg3
- ffrg4
bb0 ist BGP Internet und ICVPN Gateway, folgende Systeme haben MED Priorität über diesen Weg:
- ffrg004
- ffrg104
- ffrg5
Alles natürlich lediglich mittels BGP Priorisiert, so dass im Falle eines Ausfalls das nächst beste Gateway gewählt wird.
Sobald @thomasDOTwtf die BGP Sessions für ffrg5 und ffrg6 aktiv hat baue ich erneut die Priorisierung um, so dass immer maximal 2 VPN Gateways über 1 priorisiertes BGP Backbone Gateway routen.
IPv6 2a02 läuft über bb0, 2a03 läuft ungesteuert über ffrg0 und ffrg1, so wie bislang auch.
Die Last auf bb0 ist nun im Keller, ffrg0 und ffrg1 liegen noch deutlich unter 50% CPU Last im Schnitt.
Bandbreitenmessungen sehen sehr sehr gut aus.
Viel Spaß damit! ![]()
8 „Gefällt mir“
Vielen Dank für deine unermüdliche Arbeit @CHRlS!
Ich hoffe Du schläfst noch seelig ;-).
Gruß,
Philip
1 „Gefällt mir“
Da krieg ich ja richtig Lust, eine Ruhrgebiet-Testinstallation bei mir aufzubauen.
Wäre das ein Problem, wenn ich in Funkreichweite Rheinufer-Uplink-Nodes habe? Will keine Netzstörungen verursachen…