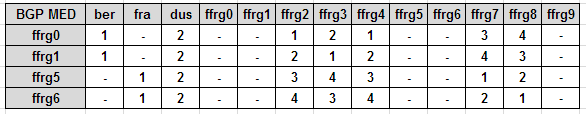Das ist eigentlich kein Problem, da die bssid sich unterscheidet und es deshalb nicht mesht.
Wenn du ganz auf der sicheren Seite sein willst, dann änderst Du noch die SSID auf "Freifunk Ruhrgebiet" o.Ä., damit Clients nicht versehentlich in das Netz wechseln können.
In lustiger Runde wurde gestern angeregt, eine „Sandkasten-Domain“ einzurichten.
Also eine, in der NUCs, Alix-Boards, Cubietrucks, handgebriegelte OpenWRTs etc. getestet werden können. Ohne dass gleich das Livenetzwerk zusammenklappt, wenn irgendwer falsche Routen announced versehentlich wegen einer bridge-Fehlconfig.
Gestern haben @thomasDOTwtf und ich zur Redundanz, wie bereits angekündigt, noch zwei weitere Supernodes ins Rheinland Backbone genommen.
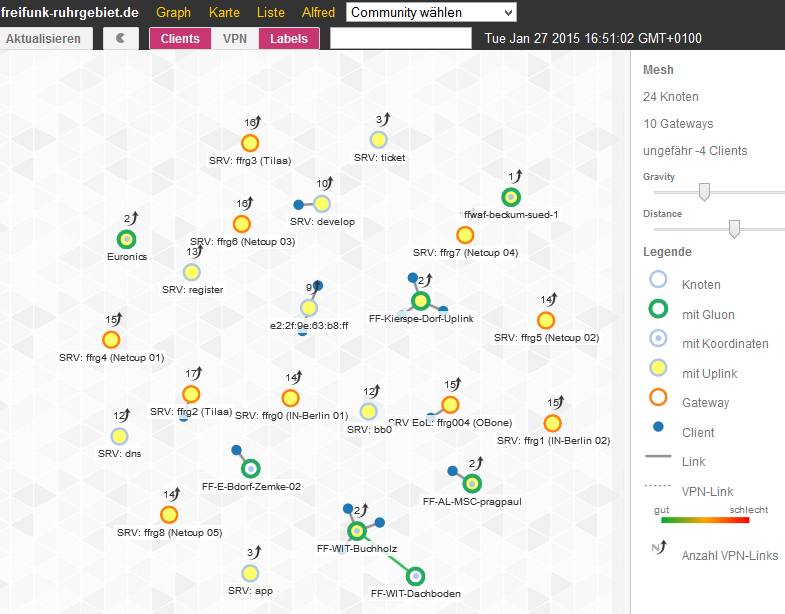
Da das Routing im Ruhrgebiet komplett dynamisch läuft habe ich nun Prioritäten im BGP auf den Supernodes eingeführt. Dadurch wird es natürlich nun ein wenig komplexer darzustellen, welche Supernode über welche Backbone Supernode läuft.
Um es dennoch nachvollziehen zu können habe ich folgende Tabelle für euch erstellt. Links stehen die Backbone Supernodes, oben die BGP Ziele unserer Backbone Standorte sowie alle Supernodes.
In den Feldern, in denen Zahlen stehen, bedeutet dies, dass diese Verbindung zum Routen genutzt wird, je niedriger die Zahl (BGP MED Wert) desto eher wird diese Route genutzt, solange sie zur Verfügung steht.
Macht es nicht mehr Sinn die Priorität von ffrg4 oder ffrg2 zu 1432 zu ändern? Sonst sind bei einem Ausfall von ffrg0 drei (+ffrg1) Supernodes auf ffrg1 und auf ffrg 5 und 6 nur jeweils einer (bzw. 2). Oder sind 0 und 1 Leistungsfähiger als 5 und 6?
Es gibt da überhaupt keine Route für um zwischen den Backbone Supernodes hin und her zu routen, das finde ich jetzt mal sehr übberraschend:
bird> show route 0.0.0.0/0
0.0.0.0/0 via 100.64.0.68 on bb-fra [fra 01:09:02] * (100/0) [AS201701i]
via 100.64.0.70 on bb-dus [dus 01:08:59] (100/0) [AS201701i]
.
@ffrg5:/etc/bird# ip r s t 42 | grep def
default via 100.64.0.68 dev bb-fra proto bird
psi@parossi:~$ ip route
default via 10.53.56.1 dev wlan0 proto static
10.53.0.0/16 dev wlan0 proto kernel scope link src 10.53.61.56 metric 9
192.168.122.0/24 dev virbr0 proto kernel scope link src 192.168.122.1
psi@parossi:~$ arp -an
? (10.53.48.1) auf 04:bf:ef:ca:ff:12 [ether] auf wlan0
? (10.53.56.1) auf 04:bf:ef:ca:ff:4e [ether] auf wlan0
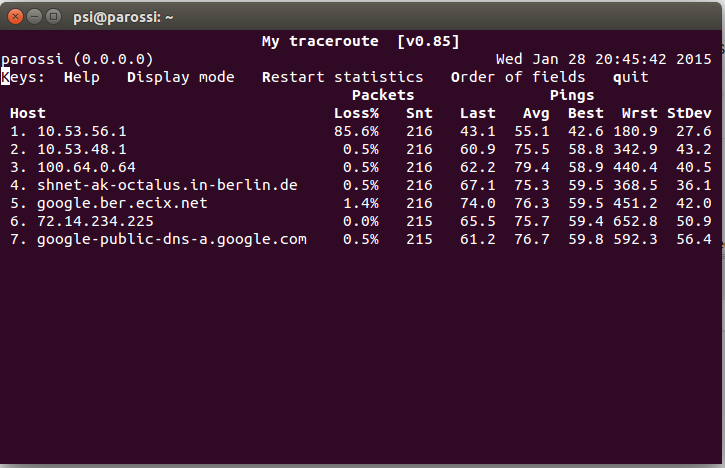
Der schickt (vielleicht) icmp-redirects, dass ich mich gleich an 10.53.48.1 wenden soll, denn die 56 routet eh zu 48. So vielleicht?
Setze ich das default-gw um, funktioniert alles viel besser …
Derzeit sagt mein Knoten übrigens:
mesh_vpn_backbone_peer_ruhrgebiet2: connected for 294183.989 seconds
mesh_vpn_backbone_peer_ruhrgebiet4: connected for 109228.948 seconds
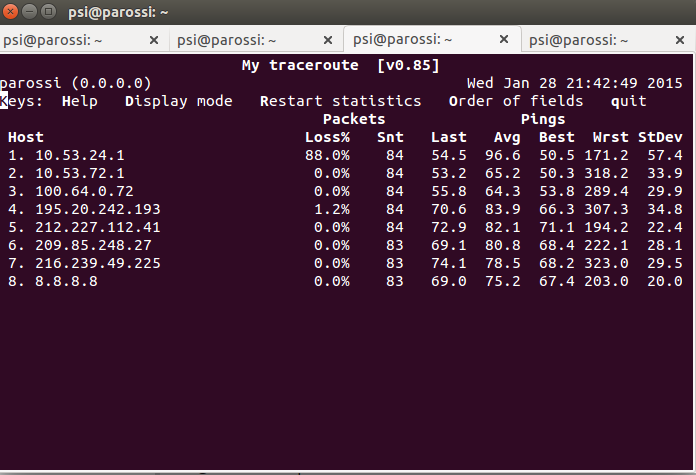
So, ffrg4 war der letzte Server, der die neue BGP Config noch nicht hatte.
Nachdem ich diese eingespielt habe ist er nun auf eine andere Verbindung gegangen:
bird> show route
0.0.0.0/0 via 10.53.64.1 on br0 [ffrg5 21:17:39] * (100/0) [AS201701i]
via 10.53.48.1 on br0 [ffrg1 21:17:41] (100/0) [AS201701i]
via 10.53.40.1 on br0 [ffrg0 21:17:41] (100/0) [AS201701i]
via 10.53.72.1 on br0 [ffrg6 21:17:39] (100/0) [AS201701i]
.
# ip r s t 42 | grep def
default via 10.53.64.1 dev br0 proto bird
Wenn Du magst könntest Du noch mal gegenprüfen wie es nun aussieht…
root@ffwaf-srv1:~# ip -6 route show 2001:4860:4860::8888
root@ffwaf-srv1:~# ip -6 route show default
default via fe80::ac53:ceff:fe18:d542 dev br0 proto kernel metric 1024 expires 1793sec
default via fe80::7c13:4fff:fe79:3742 dev br0 proto kernel metric 1024 expires 1790sec
default via fe80::60c8:d7ff:fe9a:5063 dev br0 proto kernel metric 1024 expires 1792sec
root@ffwaf-srv1:~# batctl ping 04:be:ef:ca:ff:07
PING 04:be:ef:ca:ff:07 (04:be:ef:ca:fe:07) 20(48) bytes of data
20 bytes from 04:be:ef:ca:ff:07 icmp_seq=1 ttl=49 time=18.35 ms
Reply from host 04:be:ef:ca:ff:07 timed out
Reply from host 04:be:ef:ca:ff:07 timed out
Reply from host 04:be:ef:ca:ff:07 timed out
Reply from host 04:be:ef:ca:ff:07 timed out
Reply from host 04:be:ef:ca:ff:07 timed out
20 bytes from 04:be:ef:ca:ff:07 icmp_seq=7 ttl=49 time=426.95 ms
Reply from host 04:be:ef:ca:ff:07 timed out
Reply from host 04:be:ef:ca:ff:07 timed out
20 bytes from 04:be:ef:ca:ff:07 icmp_seq=10 ttl=49 time=23.66 ms
20 bytes from 04:be:ef:ca:ff:07 icmp_seq=11 ttl=49 time=35.30 ms
Reply from host 04:be:ef:ca:ff:07 timed out
Reply from host 04:be:ef:ca:ff:07 timed out
^C— 04:be:ef:ca:ff:07 ping statistics —
14 packets transmitted, 4 received, 71% packet loss
rtt min/avg/max/mdev = 18.351/126.064/426.946/173.822 ms
Moin,
ich habe heute über verschiedene Endgeräte und verschiedene Uplinks, die über unterschiedliche Provider laufen (Telekom, 1&1,…) effektiv kein Internet weil riesig Packet loss, bis zu 95% effektiv habe ich das router verteile und bewerben temporär ausgesetzt, da ich nicht prüfen kann ob eine Installation vor ort erfolgreich war, da ich über Freifunk nicht ins Internet komme. Auch Pings auf 8.8.8.8 laufen nicht.
Naja, das MeshVPN das Du nutzt (das schließe ich jetzt mal aus Deiner Schilderung) läuft per UDP zwischen Node und Supernode.
Wenn du da jetzt dermaßen Packetloss (besser: Packet-Survival) hast bei Deinem Internetprovider, dann kann auch Freifunk das nicht mehr heilen.
Das sind dann wohl vermutlich alles Telekom/Tonline-Resale/Interconnect-Anschlüsse, wenn sowohl TOnline wie auch 1&1 betroffen sind. Also das was man gemeinhin als „Großraumstörung“ bezeichnet.
, dann
Ähm, ich habe an den Anschlüssen null packet loss, wenn ich nativ rein gehe, aber über Freifunk is dann halt Schicht im Schacht. Ich hab das atm an 3 Anschlüssen unabhängig voneienander und die liegen mal eben 100km auseinander. Also bin ich mir recht sicher, dass es nicht an einem Provider liegt sondern an FF.